
Unlocking Big Tech Secrets: How leading developers are building smarter, faster, and more scalable APIs in 2026 Register for the Webinar!
Without proper API testing, organizations expose sensitive data, invite breaches, and risk costly downtime. Our latest infographic reveals how neglected APIs can cause real-world vulnerabilities—and why proactive testing is critical.
Microservices and APIs are now everywhere, along with CI/CD, “automation” driven dashboards. These terms sound great —they feel like the logical next step—; there is a good chance your team is already planning or launching them. In fact, your team has likely made some ambitious plans to integrate and scale the existing development systems.
Poetically by using these terms and strategies your teams should be shipping confidently, but in reality, releases are still delayed, oncall rotations are messy, and production incidents keep slipping through. Something is definitely wrong here, and you are not able to locate it, and what’s worse than not knowing what the problem is with your APIs. So, if your API development cycles looks confusing, it’s important to understand how it works in practice and how to simplify and make it work.
Recent industry reports highlight a growing gap between intent and execution:
• Flaky automated tests are on the rise as suites and pipelines grow more complex.
• 99% of organizations reported at least one API security issue in the past 12 months
• API incidents are now the leading root cause of major outages across industries.
So, the problem isn’t “we don’t test APIs.” The problem is that most teams are:
• Maintaining scripts that are effortless and that can’t keep up with change.
• Testing the wrong things (lack of clarity of API functionality and purpose).
• Doing far too much manually in a world that moves too fast.
To fix it, you have to start by naming what’s actually going wrong.

Here is a pattern that we’re seeing repeats across nearly every mid-to-large engineering organization:
Once the team upgrades their API testing tool. The new version ships self-healing tests, built-in security scanning, automated contract validation, and real-time schema drift detection. The changelog is impressive.
And then the team uses it… exactly the way they used their legacy tools.
Same manually written collections. Same hardcoded tokens and URLs. Same “happy-path-only” assertions. Same nightly batch runs instead of per-commit feedback. The tools have evolved, but the underlying practices haven’t matched the pace.
This gap manifests in three specific, measurable ways:
• Test Maintenance Overload: In teams with brittle, heavily scripted suites, maintenance still consumes 40–60% of total automation time. Modern tooling offers contract-driven test generation that can slash this number—but only if teams restructure their suites to actually support it.
• Shallow CI/CD Integration: Many teams still run Postman collections locally before a deploy or rely on a single nightly run. While modern tools support deep, per-commit pipeline integration, the internal workflows often remain stuck in a manual mindset.
• Wasted Self-Healing Capabilities: When a response schema changes—a renamed property or a shifted data type—modern tools can auto-apply updates. However, teams that still hardcode every assertion by hand never trigger these capabilities, forcing them to fix every break manually.
Eventually, coverage stops growing. This isn’t because the team lacks ambition; it’s because every engineering resource is exhausted just keeping existing tests alive. To protect pipeline velocity, teams start disabling “noisy” tests. Coverage quietly erodes in the most critical areas: error handling, authentication, and performance.
Meanwhile, the few teams that have modernized their practices alongside their tools report faster releases, fewer regressions, and significantly less time spent on test maintenance.
The gap isn’t about which tool you pick. It’s about whether your testing practice has caught up to what the tool can actually do.
Every contract change—new field, new auth scheme, slightly different response—can break dozens or hundreds of tests if they’re heavily scripted and hardcoded. Studies of automation practices note that maintenance can consume 40–60% of test automation time in large suites when design is brittle.
That leads to two predictable outcomes:
• Coverage stops growing because teams are just keeping old tests alive.
• People start disabling “noisy” tests to protect the pipeline, shrinking coverage quietly.
This is the widest gap in API testing right now — and it is growing fast.
In 2026, AI-assisted test generation, anomaly detection, and MCP-powered local model integrations aren’t experimental but strategic. They ship inside tools. They power workflows at companies that are moving faster, catching deeper issues, and releasing with a fraction of the manual overhead that legacy teams still carry.
But most teams haven’t absorbed this shift. Here is what that looks like in practice:
• Test creation is still entirely manual. A developer or QA engineer reads the spec (if it exists), writes assertions by hand, and updates them by hand when something changes. Every. Single. Time.
• Flaky test diagnosis is still a human guessing game. Instead of ML-based classification that identifies patterns in test instability — timing dependencies, shared state, environment drift — teams assign someone to “look into it” during a sprint where nobody has slack.
• Coverage gaps stay invisible. Without AI analyzing traffic patterns, schema evolution, or historical incident data, teams have no systematic way to know what they’re not testing.
The dangerous gaps — around error handling, authorization edge cases, timeout behavior — stay hidden until they show up in production.
Research into ML-based flaky test classification shows promising results in identifying problematic tests automatically. But in practice, most teams don’t benefit from this intelligence yet — not because it doesn’t exist, but because their tooling and workflows haven’t been updated to use it.
Teams that still rely entirely on manual test design are not just slower. They are structurally unable to keep pace with API-first competitors who use AI to auto-generate edge-case coverage, self-heal broken tests after contract changes, and surface risk patterns humans would miss.
This is the one problem that architects understand in theory but testing teams experience in pain.
Microservices delivered on their core promise: teams can develop, deploy, and scale services independently. But that autonomy added a category of failure that traditional testing frameworks were never designed to catch.
Most failures in distributed API systems don’t happen inside a service. They happen at the boundaries where services interact.
Let’s see what this means:
Consider a simple example. Service A changes a response field — maybe a field name, maybe a format.
The change seems harmless. Service A’s tests pass. Service B’s tests also pass because nothing in its local environment changed.
But in actual practice, when Service B consumes the updated response, the system breaks. This is contract drift.
Both teams did their testing correctly — but no one tested the interaction.
Distributed systems also fail in chains. Leading to failures appearing across multiple services. This happens because no single team sees the full picture. No single test suite reproduces the issue.
This is what makes cascading failures so difficult to catch before production.
Large organizations now operate hundreds or thousands of APIs across many teams.
Without any strong governance, testing becomes fragmented because:
• Teams invent their own testing practices
• Duplicate APIs and duplicate tests emerge
• Breaking changes ripple across services without clear ownership
Over time, the system becomes harder to reason about and harder to test reliably.
The hardest problems appear when testing real workflows. Business processes like:
• Loan origination
• Claims processing
• Order fulfillment
Rarely involve a single API.
Instead, they spread in multiple services interacting in sequence.
Testing these flows requires:
• Orchestrating chains of API calls
• Maintaining state between steps
• Coordinating with external systems
These stateful, multi-service workflows remain one of the hardest areas of API testing.
Many teams still measure success by endpoint coverage. If every API endpoint has tests, the system should be stable — in theory.
But in 2026 failures don’t happen inside endpoints. They happen between services.
Testing APIs in isolation may improve coverage metrics, but it does quite little to guarantee system reliability in production.
Test Data Complexity Amplifies the Problem
Even well-designed tests become unreliable when test data is poorly managed. Shared databases, reused identifiers, and hidden dependencies between tests often lead to the classic scenario:
A test passes when run alone but fails when the entire suite runs.
What we feel is that API testing isn’t failing because teams aren’t writing tests.
It feels broken because new architectures are distributed, while many testing approaches were designed for monolithic systems.
Testing individual APIs is easy. Testing how hundreds of APIs behave together — under real conditions — is where the real challenge begins.
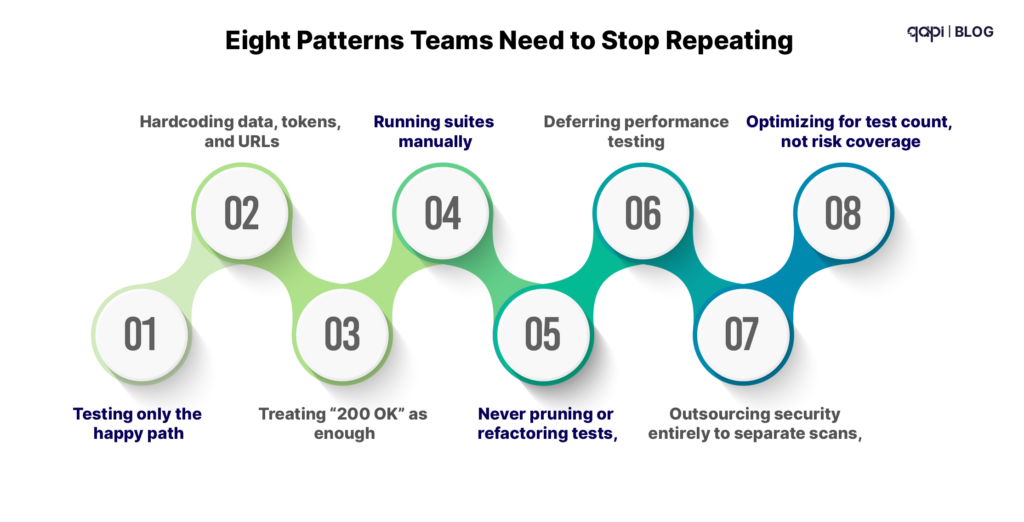
On top of those structural challenges, certain habits make everything worse:
Recognize any of those? Most teams do.
The pivot from “more tests” to “better testing” often starts with new questions:
If you don’t like your answers today, you’re not alone. But that’s also where a new approach becomes compelling.
A modern API testing practice isn’t about perfection. It’s about:
• Change aware tests driven by contracts (OpenAPI, consumer driven contracts) that flag breaking changes early.
• Risk-aligned coverage, where business-critical APIs and failure modes (security, performance, correctness) get disproportionate attention.
• CI/CD native automation, with fast, reliable feedback on every meaningful change.
• Built in functional, process and performance testing not just as separate, but all in one.
• Intelligent, agentic behavior that reduces maintenance and flakiness instead of amplifying them.
This is exactly the gap qAPI is designed to fill.
Instead of another brittle, script heavy framework, qAPI uses an agentic, AI infused approach to:
• Detect API changes and highlight what tests are now at risk.
• Reduce manual maintenance through reusing test cases where possible.
• Help teams focus on meaningful coverage—especially around orchestrated flows, security, and performance—rather than chasing raw test counts.
• Integrate deeply with modern pipelines so API tests become a reliable, fast feedback mechanism, not a lastminute hurdle.
If your current reality looks like constant flakiness, endless maintenance, and a growing sense that “we’re still blind in the riskiest places,” it’s a strong signal that your API testing strategy needs to evolve.
Want to See What Agentic API Testing Looks Like?
If you recognized yourself in more than a handful of the challenges or mistakes above, you’re exactly the kind of team qAPI was built for.
Here are three low friction next steps:
You don’t have to boil the ocean to fix API testing. But you do need tools and practices that match the complexity you’re actually operating in.
If you’re ready to move beyond fragile scripts and slow feedback into intelligent, agentic API testing, qAPI is a good place to start.
Give yourself a break before you read this blog. Let’s take a walk a few years back, to a time when you would struggle to get answers to your specific research. Didn’t you wish you had a way to find all the answers you need within a click, all in one place?
In 2026, mobile applications don’t just “search” anymore; they solve.
Whether it’s generating the perfect recipe based on the three ingredients left in your fridge, syncing health metrics across a dozen wearable devices, or providing real-time AI-driven answers to complex queries, mobile apps have become the essential “operating system” for daily life.
However, powering every one of these seamless interactions is the API—the backend engine that drives the data flow.
API testing for mobile applications is no longer just a “check-the-box” activity; it is the process that ensures these critical services perform reliably under messy, unpredictable, real-world conditions. Without robust testing, the “magic” of 2026 quickly turns into a frustrating user experience.
Let’s answer the real question: Why do you and your teammates spend so much time testing APIs, only to see a drop in user engagement? That shouldn’t be the case.
You are doing what you know best: monitoring latency, tracking error rates, and simulating loads. Yet performance still falls short during peak usage, users complain about lag, and retention suffers. –
The short answer? Your tools and the metrics you’re prioritizing might be holding you back.

The result?
Poor API performance drives massive user loss. In fact, 53% of mobile users abandon apps that take longer than 3 seconds to load, making latency, throughput, reliability, and scalability critical for survival.
Most teams focus on obvious features like load capacity or scripting languages. To truly scale, you need to dig deeper:
Curious to know which tool checks all these boxes? Teams using qAPI report 60% faster testing cycles and dramatically better mobile app performance.
Your mobile app is only as strong as its APIs. A slow or unreliable backend will turn your polished UI into a frustrating experience.
The problem is that many teams test only what they can see. They polish animations, tune layouts, and squash UI bugs. But the “heartbeat” of a mobile app—and its most common point of failure—lies in:
When these APIs misbehave, the UI is the least of your problems.
Let’s look at the specific dimensions API testing brings to the development process.
In the mobile world, latency isn’t just a number on a dashboard; it’s the difference between a completed checkout and an abandoned cart.
If a user taps “Pay” and a slow API call blocks the entire screen, the app feels frozen. Users don’t see “latency”—they see a broken app. Most teams miss this because they test for success responses (status 200) but ignore response times under real-world pressure. In production, those extra milliseconds add up quickly, especially across chained APIs.
Google’s research continues to show that even micro-delays have a massive impact on user abandonment (source).
APIs are usually built and tested in “perfect” conditions: stable office Wi-Fi and low-latency environments. But your users live in the real world:
If APIs aren’t tested for retries, idempotency, and partial failures, you get duplicate transactions, corrupted data, and the “dreaded” endless loading screen.
According to the Ericsson Mobility Report, network variability contributes to a significant portion of failed mobile sessions (Ericsson). Users rarely blame the network—they blame the app.
A heavy API response does more than just slow down the app; it actively degrades the device’s health:
Older devices feel this pain first.
Yet most teams never test payload size, over-fetching, or response efficiency. They validate correctness — not cost.
GSMA research shows inefficient mobile data usage directly impacts engagement and retention.
If your API returns more than the screen needs, your users pay the price.
Authentication flows usually work fine during the “happy path” of logging in. The real failures happen at the edges:
The result is random logouts that feel like “bugs” to the user. The Verizon Data Breach Investigations Report consistently highlights authentication issues as a top API risk. Testing auth once at login isn’t enough; you must validate the entire token lifecycle under stress.
Data is the purest form of proof. Most APIs behave perfectly with ten test users or a small beta group. But growth changes the rules. When traffic spikes during a launch, queues back up and dependencies fail.
If your APIs aren’t load-tested independently of the UI, you’re essentially waiting for your users to tell you when you’ve reached your limit.
Imagine you and a teammate working on the same test case. You add new fields, update endpoints, and refine the dataset.
Later, you realize their changes overwrote yours entirely. You’ve got no alerts, no warning, but still you lost your entire progress.
Users might see missing updates, overwritten changes, or corrupted data across devices, as in note-taking apps where offline edits don’t sync properly.
This destroys trust instantly. A study by the Mobile Ecosystem Forum (2025) found that 40% of mobile app complaints involve sync issues. Offline support is one of the hardest problems in mobile development. Without rigorous API testing:
Once trust is lost, it is rarely regained.
Every row in the table below represents an avoidable cost. In 2026, mobile performance is no longer decided by UI polish; it is decided at the API layer.
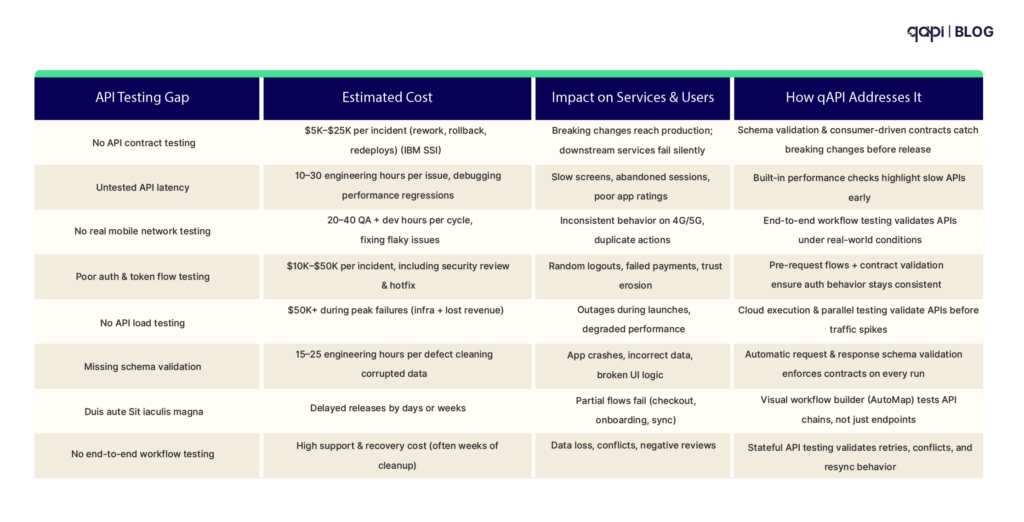
Every screen load, tap, and background sync depends on APIs behaving predictably under real-world conditions—scale, network instability, and evolving contracts. When APIs fail, no amount of frontend optimization can save the user experience.
Mobile users don’t care about your architecture. They care about whether the app works — every single time.
Avoid These Failures with qAPI
Most teams don’t struggle because they lack tools. They struggle because their tools don’t reflect how mobile systems actually behave.
Relying only on mobile app performance testing tools open source or basic mobile application performance testing tools open source can help at an early stage—but these tools often focus on isolated performance checks, not real API-driven workflows.
They rarely catch issues like schema drift, chained API failures, or data inconsistency across sessions.
Similarly, many performance testing tools for Android apps and performance testing tools for Android mobile applications measure screen-level behavior. They miss what’s happening underneath: API latency, contract breaks, and sync issues.
This is where qAPI changes the approach.
qAPI helps teams:
By shifting testing to the API layer—and making it part of every run—teams stop reacting to production issues and start preventing them.
The result? Faster releases, fewer incidents, and mobile apps that feel consistently fast and reliable—no matter the device, network, or scale.
When someone asks “How would you scale a REST API to serve 10,000 requests?”, they’re really asking how to keep the API fast, reliable, and affordable under heavy load.
This question comes up because REST APIs—especially in Node.js—are easy to build but harder to scale. Everything works fine with 10 requests per second, but as you try to scale to 10,000+ requests per second, your setups will show all the red flags.
This tutorial will walk you through the most practical, repeatable and effective ways to handle REST APIs on qAPI that will help you improve your API testing lifecycle.
“Scaling a REST API to handle tens of thousands of requests per second is less about chasing a specific number and more about building the right foundations early. “
What we see across multiple APIs don’t fail because of bad logic; they fail because they were designed for today’s traffic, but not tested tomorrow’s growth.
REST APIs dominate because they’re simple enough for beginners yet powerful enough for Netflix-scale systems. While GraphQL, SOAP, and RPC have their strengths, REST hits the sweet spot of simplicity, tooling support, and developer familiarity that makes it the default choice for 70% of modern APIs.
So let’s see how teams should actually handle them.
Step 1:The first principle is understanding what your application server is actually good at.
Event-driven servers are designed to handle large numbers of concurrent connections efficiently, but the only catch is that they have to be used correctly.
They excel at I/O-heavy workloads, such as handling HTTP requests, calling databases, or talking to other services. Problems begin when CPU-heavy or blocking operations are introduced into request paths.
When that happens, concurrency drops sharply and latency increases rapidly. The lesson here is simple: keep request handling lightweight and push heavy computation out of the critical path.
Step 2: Next, plan for horizontal scaling from day one.
What I mean is instead of relying on a single powerful server, you should build your own system so multiple identical instances can serve traffic in parallel. This will help to add capacity gradually and recover easily from failures.
Horizontal scaling only works when your API is stateless. Every request should carry all the information needed to process it, without depending on in-memory sessions or server-specific state.
Step 3: Once the API layer is sound, attention must shift to the database.
Because this is where most systems hit their limits. APIs can often handle high request rates, but databases cannot tolerate inefficient queries at scale.
Poor indexing, unbounded queries, or mixing heavy reads and writes in a single datastore can quickly become your worst enemy. To scale safely, queries must be predictable, indexed, and measured.
In many cases, separating read and write workloads or reducing database dependency through smarter access patterns makes a bigger difference than optimizing application code.
Step 4: Caching is one of the most effective tools for reducing load and improving performance.
Not every request needs fresh data, and many responses are identical across users or time windows. By caching these responses at the right layers, you remove the need for unnecessary computation and database traffic.
This helps to reduce latency for users and increases capacity for handling truly dynamic requests. In short, effective caching is intentional, with clear rules around expiration, invalidation, and scope.
As traffic grows, protecting the system becomes just as important as serving it. Rate limiting ensures that no single client or integration can overload your API, whether through misuse, bugs, or unexpected retries.
It’s quite clear that without respectable limits, small failures can bring large outages. With limits in place, the system can slow down gracefully instead of collapsing like dominoes.
API Testing is where many teams underestimate risk. Because APIs will behave well in development but fail under real-world conditions as local tests lack concurrency, volume, and failure scenarios.
When APIs scale the retries overlap, timeouts compound, and small delays create more issues. This is why scalable systems validate not just correctness, but behavior under load. Performance characteristics, error handling, and edge cases must be understood before users discover them.
You cannot scale what you cannot see. Tracking latency, error rates, and traffic patterns at the endpoint level allows teams to detect stress before it turns into downtime. More importantly, it helps identify which parts of the system break first under pressure.
When teams rely only on general metrics, failures will feel sudden and mysterious to you. But when visibility is built in, scaling will give you a controlled process rather than the prior.
Ultimately, scaling an API is not a single decision or a one-time optimization. It is the result of strategic architectural choices that prioritize statelessness, ensure performance, and system-wide resilience. Teams that scale successfully do not wait for traffic to expose weaknesses; they design for those weaknesses in advance.
The goal is not to handle a specific number of requests per second. The goal is to build an API that continues to behave predictably as usage grows, complexity increases, and conditions change. When that mindset is in place, scale becomes an engineering problem you can plan for, not a crisis you react to.
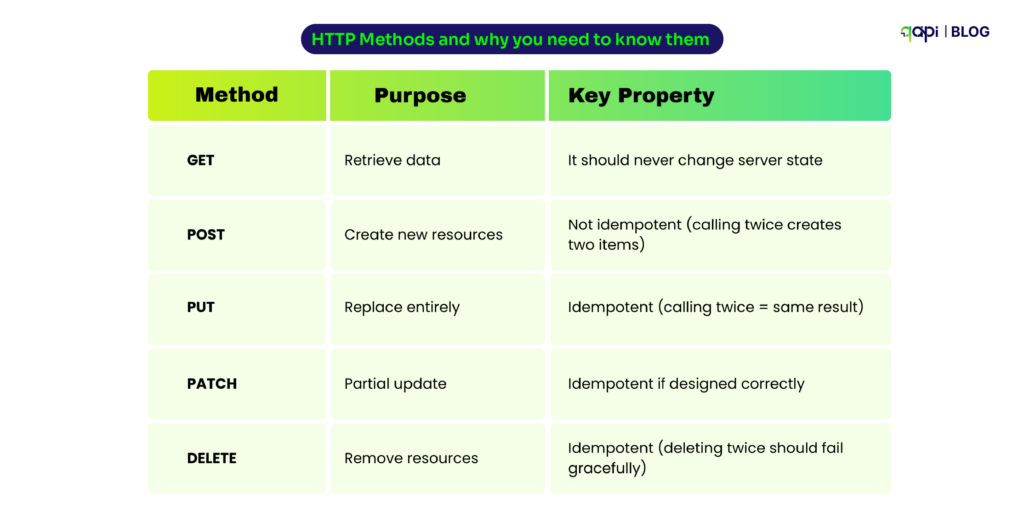
Here’s what trips up even experienced developers, we a similar pattern and listed down some of the major problems that they frequently face:
GET requests with hidden side effects If your GET endpoint is able to logs analytics, updates counters, or does anything beyond returning data, you’ll break caching. So, clients and CDNs expect GET to be safe and repeatable.
POST vs. PUT confusion When clients retry to execute failed POST requests, duplicates are created. PUT is replaces safely. Choosing the wrong method means users accidentally ordering the same item twice.
Non-idempotent DELETE operations If deleting a resource once works but deleting it again returns an error, clients can’t retry safely. Well-designed DELETE operations handle “already gone” gracefully.
The Simple Process that teams should have: Thinking About Retries
Every production incident teaches you the same lesson: network calls fail, and clients retry.
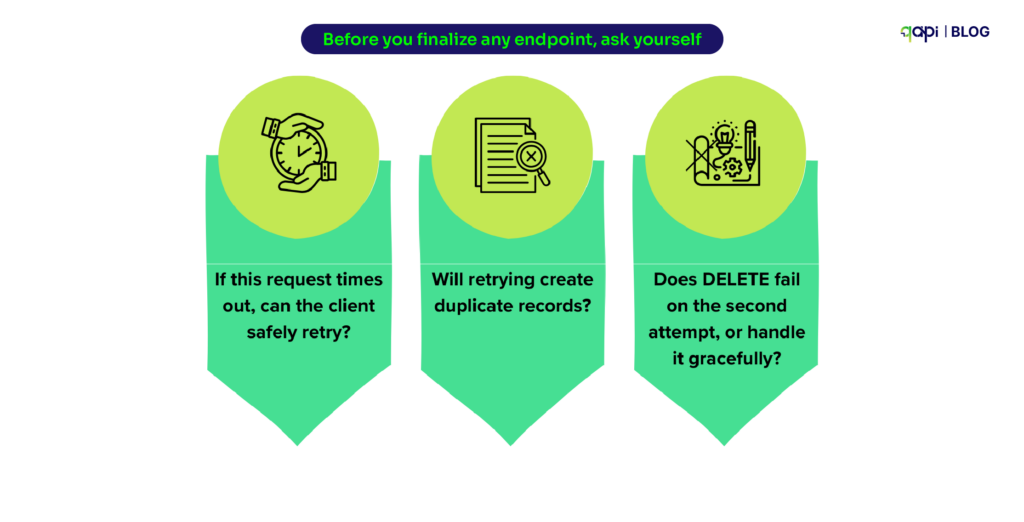
Before you finalize any endpoint, ask yourself:
qAPI tip: Send the same POST request twice. If it creates two resources, document that behavior. Your API consumers need to know.
Chatty APIs Requiring 10 requests to render one screen. Each round trip will add latency, and the chances of failure increase.
God Endpoints Too much dependency on one endpoint: POST /processEverything. It becomes harder to test APIs and much harder to maintain.
Leaky Abstractions Exposing database JOIN results directly as API responses. Your internal schema becomes a public contract.
Ignoring HTTP Semantics Teams use POST for everything or returning 200 OK with error payloads. This confuses clients and breaks caching.
No Pagination Returning unbounded arrays that crash mobile apps when users scroll.
Tight Coupling Designing APIs around one specific client. When that client changes, your API breaks.
qAPI tip: We recommend that if your tests require a complex multi-step setup, your API design might be the problem. So ensure your so-called “good” APIs are testable.
Now that you know what to do and what not to do, here’s a checklist to keep handy.




Two hard realities drive the case for automated (API) testing:
If your pipelines aren’t automatically validating API behavior at every merge and deploy, you’re effectively accepting a higher probability of costly production incidents.
The Hidden Tax You Can Eliminate: Endless Test Maintenance
Many organizations have/are “automate everything” and ended up with the maintenance spiral: brittle assertions, hardcoded payloads, failing tests after harmless changes. The result is toil: engineers stop trusting tests, and CI becomes noisy.
What actually breaks the cycle:
When teams adopt these patterns, maintenance drops, signaltonoise improves, and developers treat CI failures as actionable reality, not background hum.
The software market is building on a simple truth: APIs are where business happens—and automated API testing is how you protect that business while moving faster. The data is unambiguous: API adoption and AIdriven traffic are rising, visibility gaps persist, incidents are frequent and expensive, and high performers prove that speed and stability can (and should) rise together.
If you modernize testing around contracts, change awareness, behavior learning, and CI/CD guardrails, you’ll break the maintenance spiral, reduce risk, and ship confident changes continuously. That’s the future customers (and CFOs) will reward. And you can do all that and still some more with ease on qAPI.
The product is a hit but now you have new problems. How much traffic can the current APIs handle? How many APIs need changes? And how do you track it over time?
These questions aren’t easy to answer, but as a founder/product owner, a goal that everyone would like to find themselves in.
You’ve just reached your 3-year goal in a single year. Now it’s time to lock in and make decisions that will lay the foundation for the product’s future. Congrats — now your APIs are about to get absolutely hammered.
According to SQmagazine many companies now handle 50–500M API calls per month at an average. That’s ~19–193 requests/second peaks are often 5–15x higher.
But with this growth there are a few key areas that we should be on the lookout for, let’s look at this closely:
As API traffic grows, most teams hit the same wall: at some point in time: systems that usually worked at a few hundred requests per second start slowing down, error rates increase.
This is a classic API scalability problem, but the issue isn’t related to volume; it’s that high-traffic APIs behave very differently under pressure than they do in normal conditions.
A big part of this comes down to how the API is scaled. Many teams start with Vertical Scaling—adding more CPU or memory to a single server. While this provides short-term relief, it has hard limits and gets expensive fast.
Horizontal scaling, on the other hand, allows you to add more instances as traffic grows by spreading the load across multiple machines..
But here’s the catch: horizontal scaling works best when APIs are stateless, This means any request can be handled by any instance without relying on local memory or session data.
Context: Stateless design is what makes an API truly scalable at high traffic levels.
Load balancing is the most effective way to manage costs. Instead of overloading one server, a load balancer distributes incoming API requests evenly across healthy instances. When traffic spikes, auto-scaling groups can spin up new instances automatically and remove them when demand drops.
This ensures your high-traffic APIs stay responsive without forcing you to pay for peak-capacity hardware all year long. Your goal as a product owner isn’t just to survive a single traffic spike; it’s to handle fluctuating traffic every single day.
The biggest mindset shift is designing for change, not just for peak numbers. Many teams size infrastructure for “maximum traffic” and hope it covers future growth. In reality, API traffic growth is uneven.
Flash sales, product launches, partner integrations, and viral campaigns create sudden bursts that basic setups can’t handle efficiently.
By building scalable APIs that expand automatically, your performance stays stable while API cost optimization.
As teams grow from a single squad to multiple cross-functional groups, the challenge of scaling APIs shifts from infrastructure to design consistency and governance.
However, once infrastructure stops being the limiting factor, a different problem emerges: API design issues. When every team defines its own API patterns, surface conventions, error formats, and versioning strategies, the ecosystem becomes a mess.
This design gap slows down – integration, increases cognitive load for developers, and kills reusability. Research shows that without strong API governance, reusability can drop by more than 30% in large organizations.
To solve this, teams must scale along two dimensions: the system (to handle workload growth) and the design (to maintain consistency).
On the design side, teams must adopt API style guides that define URL structures, pagination schemes, error objects, naming consistency, pagination standards, authentication flows, and versioning rules.
These guides help you ensure in future that whether API X was built by Team A or Team B, it behaves predictably and integrates cleanly.
Design governance should also be followed by a dedicated group for review processes and contract-first validation. Rather than detecting breaking changes in staging or production, teams should validate API contracts early, ideally during CI runs. This prevents minor changes, like a renamed field or changed response order, from becoming major issue at scale.
Companies with formal API governance and contract validation report fewer integration failures and smoother scaling during peak traffic events, according to API industry reports.
We’ve looked at how to grow your APIs infrastructure, manage costs, and handle design and governance specifications. Once these are done, the only challenge that remains is testing them.
With API testing, you put your APIs through a series of tests to ensure they work as designed. To test the limitations, there are several types of tests, so mature teams don’t just check if the API works.
They will confirm if it is reliable, secure, and delivers on its business promise. This is how teams should plan to test their APIs once the design process begins.
Functional tests ensure the API always matches the expected output.
| Focus Area | Example |
|---|---|
| Endpoint Behavior | If you ask for information (GET), you will get information. If you ask to change something (POST/PUT), you should confirm the change happened exactly as requested. |
| HTTP Method | Ensure measures are in place to validate that unauthorized POST requests are rejected with a 405 Method Not Allowed, and that PUT is used for full replacements rather than partial updates (which should be PATCH). |
| Expected Schema | Validate that the response structure for a successful transaction includes all required fields, as specified in the OpenAPI/Swagger documentation. |
Let’s look at it closely, because wrong data spreads silently and is extremely hard to fix later. So when your API usage grows ensure to run data accuracy checks. Here are some examples that you can use as a reference:
| Focus Area | Example |
|---|---|
| Calculated Values | If an API calculates sales tax or discounts, test the logic against known financial benchmarks. For example, updating a customer’s address must reflect that exact change in the database immediately. |
| Persistence Verification | After a PUT /inventory/{sku} update, run a follow-up query on the database layer (or a separate read-only API) to confirm the write transaction committed the value correctly. |
| Data Type Fidelity | Validate that fields intended as a Big Decimal (e.g., currency) are not accidentally converted to floating-point numbers, which introduces rounding errors that are invisible at the surface level. |
To build high-quality software, teams will have to go beyond to see if an API returns a response and focus on enforcing real business logic through API testing. Business logic refers to the rules and workflows that reflect how a real application should behave in real use cases.
When business logic fails, entire processes—from order handling to payments—can break your product, even if the API itself technically “works.”
| Focus Area | Example |
|---|---|
| Workflow | In a typical order lifecycle, confirming that an order status cannot transition directly from PENDING to SHIPPED without first passing through PROCESSING. |
| Eligibility Checks | If a customer is tagged as “Bronze”, the API should automatically reject any request for “Platinum-only” features, even if the request is technically valid in every other way. |
| Rate Limiting & Limits | If an API allows 10 withdrawals -per minute—the first 10 go through successfully, but the 11th request must be blocked with a 429 Too Many Requests error. |
Another key measure is integrating automated testing into the development workflow. API automation enables teams to run these logic-focused tests every time code changes are made, giving fast, reliable feedback without adding manual burden.
Automated API tests run in seconds compared with much slower UI tests, sometimes up to 35× faster, enabling more frequent checks and broader coverage across business rules and edge conditions.
This drastically improves confidence in releases because of the logic paths that matter most—such as eligibility checks for premium features or rate limiting thresholds—are deployed at scale with less to no human intervention.
Teams should also treat API testing as an important flagging metric, and start to define it’s own guardrails to ensure product stability and increase customer retention. Because APIs operate independently from user interfaces, it is a good practice to test API logic before the UI is even built, allowing logic issues to be caught early when they are cheaper and easier to fix.
Early testing of business logic through automated testing tools integrated into CI/CD pipelines ensures that every change reinforces—or at least does not break—the expected real-world behavior.
Finally, “teams should measure and evolve their API testing strategy”
Because at the end of the day, enforcing business logic in API testing is not optional—it’s essential to sustainable software quality and fast delivery cycles, and robust automated testing practices are the most effective ways to achieve stability at scale.
| Focus Area | Example |
|---|---|
| Latency Consistency | Measure the 95th and 99th percentile response times, not just the average to check the average consistency. |
| Stress Testing & Saturation | Put load that exceeds documented throughput (e.g., sending 150% of expected peak traffic) to confirm the API returns 503 Service Unavailable, rather than corrupting data or crashing. |
In short: You don’t—at least not by following the docs.
Outdated or missing docs forces teams to guess behavior, hunt for old specs or re-learn things the system already knows.
Instead, teams should observe how the API actually behaves (we’ve already talked about this above) by sending real requests, inspecting real responses, and treating runtime behavior as a reference point.
With qAPI’s AI summarizer, you get a complete AI -assistance that makes it easier for you to populate documentation end-to-end and understand what the API is designed to do.
You test them as one continuous flow, not as separate calls, because that’s how real users experience the system. In most applications, one API depends on data from another, so a single failure can break the entire journey.
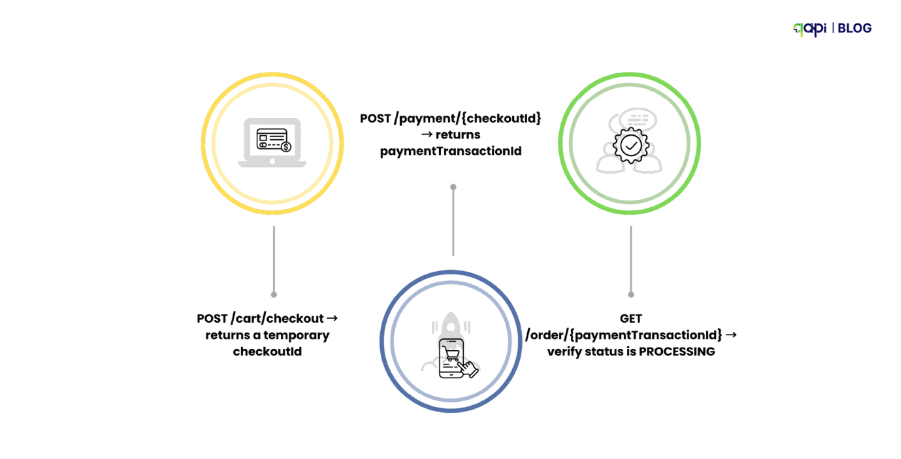
Example (E-commerce Checkout):
The most critical test here is what happens when something fails. If the payment is declined in step 2, the system should clean up properly—mark the cart as abandoned or roll back the checkout—rather than leaving the order in an incomplete state.
This matters a lot because broken workflows cause data inconsistencies, failed orders, and customer frustration – something businesses ignores when growth becomes too big to handle.
Growing teams often assume API scaling is a future problem—something to solve once traffic explodes or systems slow down.
Just like Google search has shifted from “pages” to “answers,” new systems have shifted from UI-driven flows to API-driven architectures. If you’re not testing APIs with scale in mind early on, you’re already digging your own grave.
Mature teams don’t wait for failures to tell them their APIs don’t scale. They instrument, test, and observe continuously. This level of ownership turns API testing from a defensive task into a strategic advantage: it tells teams where they will break next, not just where they broke last time.
Your approach to scaling APIs depends on what you want to protect.
If it’s reliability, you focus on load, rate limits, and graceful failure. If it’s velocity, you invest in automated testing that runs on every change and across every dependent service. If it’s cost and performance, you measure real request patterns instead of assumptions.
It is simple if you state out what you want.
We’re in a similar messy middle with APIs as we are with AI-driven search: patterns are changing faster than best practices can keep up.
Teams that start treating API testing as a first-class scaling strategy today will have a massive advantage tomorrow.— When the growth hits, you won’t be guessing. You’ll already know.
After many years, AI has made it possible to develop and deploy application in days.
With just a couple of tools, API development was streamlined; you can design, test, and deploy if you have the right set of tools. A solo developer or a team could develop an application and backend without breaking a sweat.
What started out as revolutionary has now created its own set of problems.
Only a fraction of people are able to deploy on time and maintain upkeep.
When we are creating and developing APIs much faster than we did, designing alone isn’t enough. Instead, we are avoiding the work we must put in testing them, the visibility needed to see how APIs perform in actual traffic.
API testing is non-negotiable in 2026.
If you visit Reddit or StackOverflow, there’s a massive drop in the questions we’ve asked around API testing and effective ways to do it. For example, here’s a user asking a basic question.
I agree with people’s thoughts presented in such forums, because there’s no clear cut or right step-by-step approach to API testing.
How does one know what’s the best tool or the best API testing method is? And how does one develop and replicate that practice?
So, here’s this blog post to make it simple.
First things first, testing is just not about doing functionality checks.
The problem is that we don’t test in ways that scale.
Either the teams are all in with manual testing practices, running in circles and are already exhausted. Or they are spending time rechecking or validating what their automated testing tool missed.
The first thing that we already talked about is flaky tests, which reduces confidence in the entire CI/CD process. These tests pass intermittently—often succeeding on reruns without changes—due to race conditions, shared or unstable test data, inconsistent environments, or unreliable external dependencies.
The result is clogged pipelines, delayed deployments, and a growing tendency for engineers to ignore legitimate failures.
The second bottleneck is excessive test maintenance. Teams often spend 40-60% of their QA time simply repairing broken tests. This occurs when tests are basic: they rely on hardcoded data, make overly precise assertions, are tightly coupled to implementation details, or use expired fixtures.
Even a minor change in the application can thus trigger widespread test failures, slowing down release cycles and accruing significant technical debt.
A snowball effect, for all the wrong reasons.
The third issue is dangerous coverage gaps. While happy-path scenarios are usually well-tested, critical areas such as error handling, edge cases, security checks, and performance under load remain insufficiently covered.
This happens because maintenance burdens crowd out the creation of new tests, and it is difficult to safely simulate complex real-world conditions. Consequently, bugs and vulnerabilities often go undetected until they reach production.
We’re just hitting the major concerns while the list goes on and on.
As API testing is often still a semimanual checkpoint near the end of a release:
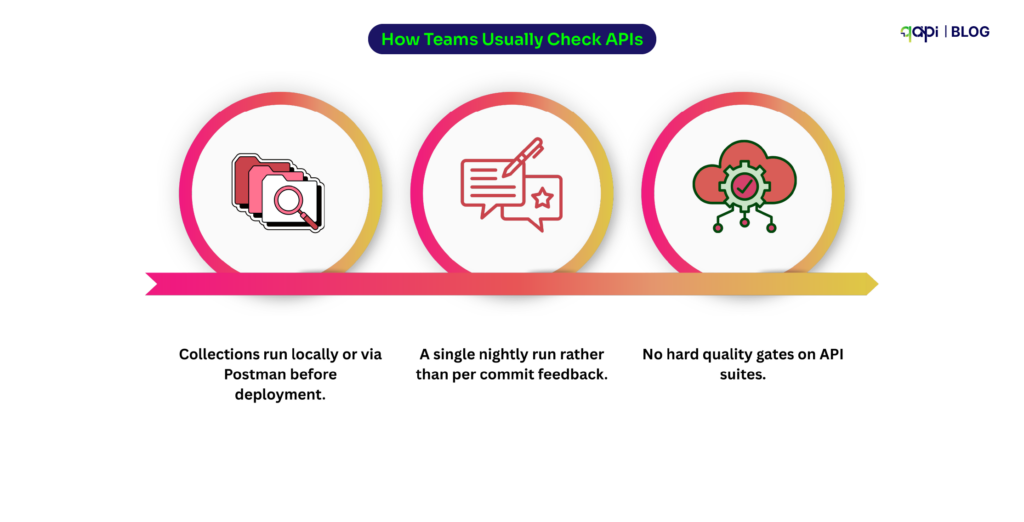
• Collections run locally or via Postman before deployment.
• A single nightly run rather than per commit feedback.
• No hard quality gates on API suites.
Often led to the said problems and more
While functional tests answer, “does it work?” and performance tests answer, “will it still work when it matters?” Many teams never systematically test and just pick one in random:
• Assume a peak traffic simulation before a major sale.
• You randomly pick a long-running test to check for obvious memory leaks and miss the rest.
• A partial load test on a complex workflow, without realistic concurrency.
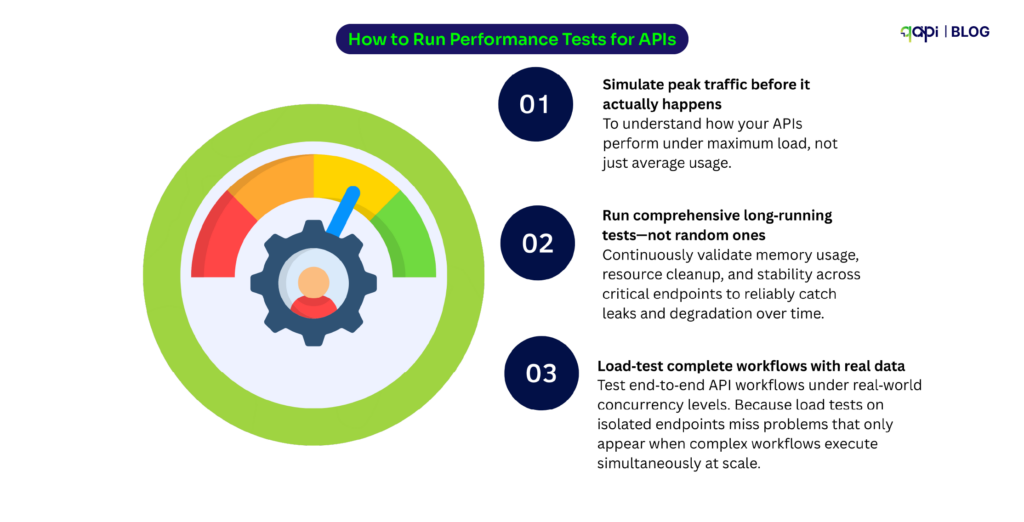
The result? You have results and you have a new set of problems.
And the worst part is, you don’t know how to connect the dots, because data is cluttered.
Microservices architecture multiplies testing complexity because multiple teams start building services independently. This leads to variation in coding standards, testing procedures, and tooling.
This further affects the environment configuration drift between dev, test, and production creating hard-to-debug issues.
Next, performance testing becomes distributed – QA teams are now forced to verify individual service functions and smooth inter-service communication.
Test interdependencies grow – one service’s failure leads to across integration tests.
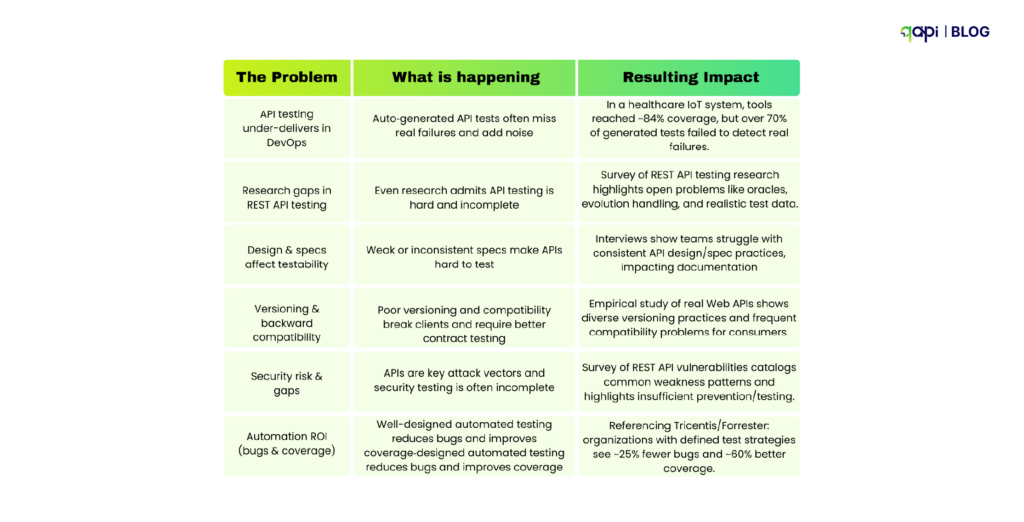
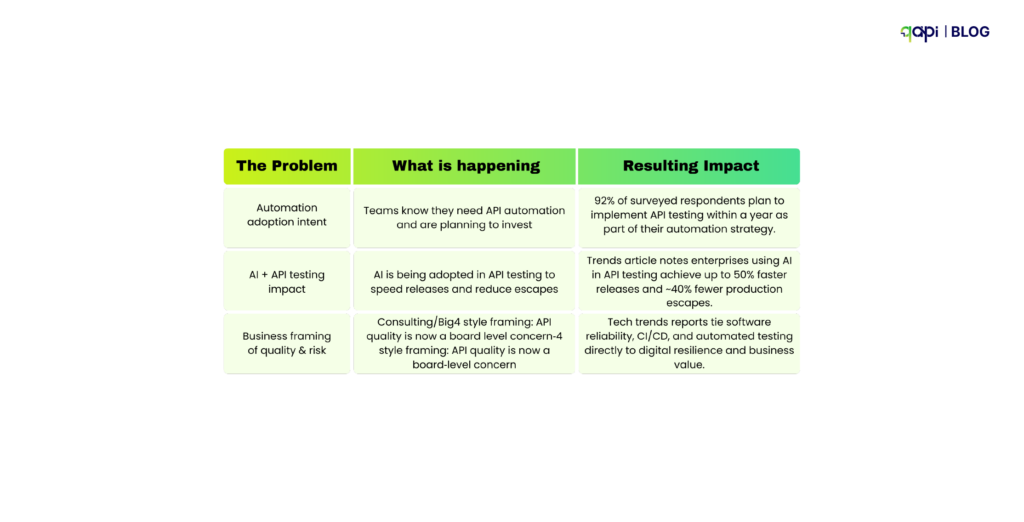
This is why API performance issues are so hard to diagnose in microservices environments—and why many teams delay addressing them altogether. In fact, 43% of enterprises report postponing API testing initiatives due to insufficient technical capability, not lack of intent.
Despite criticality, 91% of developers and testers say API testing is critical, yet 50% lack the tools and processes to effectively automate it. The adoption landscape reveals:
My take. You need to reduce and simplify.
After all, like me, you’ve been on the internet and in some cases for a longer period than me. Add your years of reading, YouTube, podcasts, and even Reddit scrolls, and you would have consumed enough to know what you’ve just been convinced enough that this is the way it has to be.
So, you’d want to start by reflecting on what is killing your teams.
Time? Budget? Complexity? Context switching? And you’ve seen the end result it has.
You already have somewhat a clear idea of what needs to go, now you need to see what a good replacement can be.
You should start with a simplified API testing tool.
You don’t want to just jump into a tool. You want to understand why they’re good. Or why they’re not good. You want to be able to explain your choice in specific details.
That’s why we’re running a free trial for all the new users and enterprises.
There’s no way around it. You have to make a lot of strategic decisions (some good, some bad, but mostly wise) before your need becomes obsolete.
Every time you do, every time you analyze your work, you’re practicing and building a system that will help you and your team immensely.
Judgment only improves with volume. You want to do run 100 tests. Write 100 test cases. Generate 100 reports. Edit endpoints 100 times on the dashboard.
And when AI does most of the legwork, running an extra 160 tests doesn’t feel like a thing, and you feel like you’re only getting started. That’s what qAPI does for you.
Final thoughts
Industry data shows that formal API contract testing adoption remains low. The reason is not awareness—it’s friction. Today contract testing requires additional frameworks, cross-team coordination, and ongoing maintenance.
In a world where everyone can create, this creates an adoption barrier that rarely clears.
qAPI embeds contract validation directly into everyday API testing through schema validation. This removes the need for parallel tooling and allows teams to detect breaking changes early, without increasing operational complexity or requiring specialized DevOps investment.
The companies that will win are the once that slow down, make the change and move on.
Reduce Noise in Engineering Pipelines
One of the most common complaints from engineering teams is that automated testing produces too much acceptable content that we usually forget. Tests pass, fail, and rerun—yet real production issues still escape.
The root cause that I see is a small testing focus. Many tools validate endpoints in isolation, missing failures that only appear across business workflows.
qAPI shifts testing from endpoint verification to end-to-end API workflows. It puts the work by aligning test coverage with how systems actually operate. This improves signal quality and allows engineering teams to trust test results as a basis for release decisions.
Address the Test Maintenance Costs
At scale, test automation often becomes a cost centre. Enterprises routinely spend close 60% or more of QA capacity maintaining existing tests rather than improving quality.
For you and your team this means:
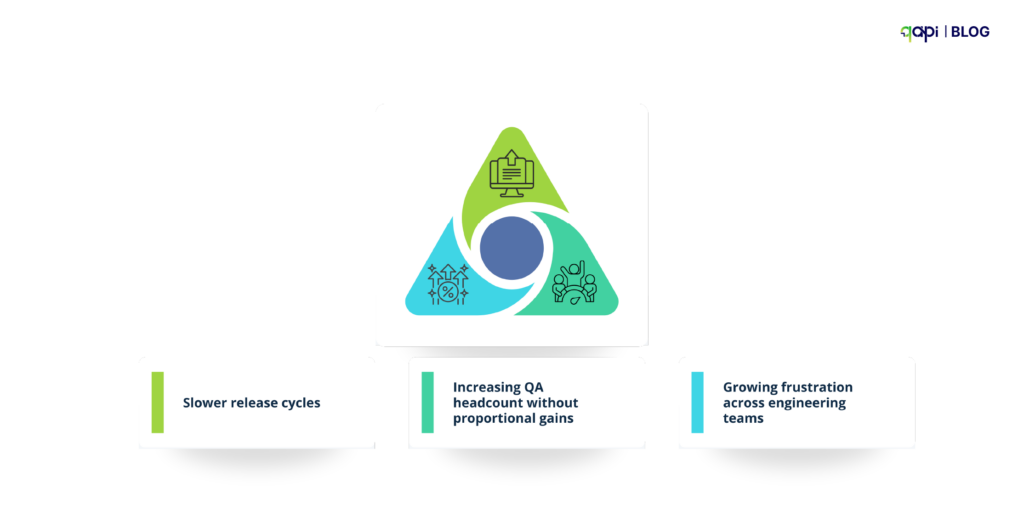
• Slower release cycles
• Increasing QA headcount without proportional gains
• Growing frustration across engineering teams
qAPI reduces maintenance effort by eliminating script-heavy test design and relying on schemas and flows that naturally evolve with the system. This doesn’t eliminate maintenance—but it meaningfully reduces it, allowing QA capacity to shift toward coverage, performance, and risk mitigation.
The ROI comes from smart allocation of effort, not from cost-cutting.
Stabilize your CI/CD as a Governance Mechanism
CI/CD pipelines are often framed as productivity tools, but at the top level, they are looked as governance mechanisms. When pipelines are unreliable, teams bypass controls, and quality reduces drastically.
qAPI improves pipeline reliability by producing deterministic results tied to contracts and flows rather than fragile assertions. For leadership, this means pipelines regain their role as trusted quality gates, enabling faster decision-making without compromising standards.
qAPI provides a combined view of API interactions across services, enabling teams to see dependencies, execution paths, and failure propagation. This visibility supports better architectural decisions and reduces dependence on old data.
By applying intelligence in adaptive ways—simplifying test creation, highlighting impactful changes, and improving failure analysis—without affecting system behavior or removing human oversight, qAPI keeps you in complete control and free of efforts.
When we talk about contract testing, it often looks and sounds more complicated than it actually is. The term itself has grown layers of jargon over the years, which is why many teams either misunderstand it or avoid it altogether.
At its core, contract testing is simply about verifying that two systems can reliably communicate with each other—without having to deploy and run both systems at the same time.
To understand it clearly, in this article we’ll discuss how contract testing helps to place them in context alongside other testing levels.
Let’s talk about unit tests first; they work on a single function or method. It checks whether a small piece of logic behaves correctly in isolation. Unit tests are fast, deterministic, and sufficient for validating internal logic. The only problem is that they stop at the boundaries of a single codebase.
On the other hand, a contract test operates one level above unit tests. It is concerned not with internal logic, but with how one service will interact with another service.
If you are a restaurant and it depends on the chef, a contract test allows you to define and verify what that interaction will look like—even if chef is not working or not yet hired.
In practical terms, this means you can simulate chef’s expected behavior based on an agreed contract. If you specify:
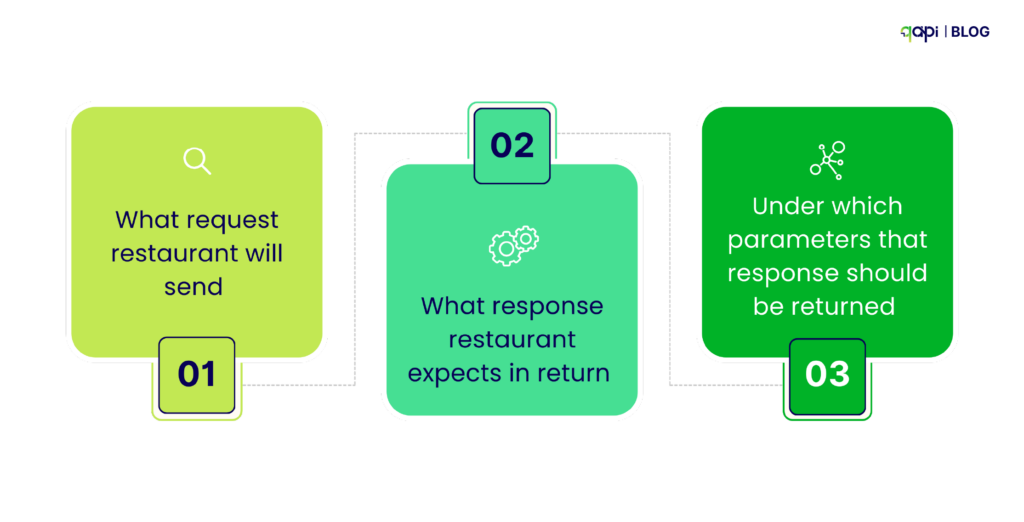
• What request restaurant will send
• What response restaurant expects in return
• Under which parameters that response should be returned
If chef later changes something(like the menu) that violates this agreement—such as removing a field, changing a response code, or altering behavior—the contract test fails immediately.
You can see the breakage early, clearly, and in isolation, rather than finding it days later during integration testing or, worse, in production.
This is why teams need to realize the value of contract testing: it detects communication failures before services are integrated.
A common point of confusion is the difference between contract tests and integration tests.
With an integration test requires both restaurant and chef to be fully implemented, deployed, configured, and running. It validates that real services can talk to each other in a real environment.
While integration tests are valuable, they are comparatively slower, fragile, and harder to debug because failures can be caused by environment issues, data setup problems, or unrelated changes in either service.
Contract tests completely avoids these problems. They allow each service to be tested independently, based on a shared agreement.
This makes contract tests faster, more reliable, and more easier to maintain as time passes, especially in microservice architectures where dozens or hundreds of services can grow at once.
Now, let’s clear the air by explaining how schema tests are different
We see many QA teams believing they are doing contract testing because they validate API schemas. This is an understandable mistake—but it is still a very big mistake.
Why? Because schema tests verify structure, not behavior. They can confirm requests and responses to a defined format: correct data types, required fields present, and to check if allowed values are respected.
This is useful, but it does not prove that two systems actually agree on how the API should behave in real scenarios.
A schema test will tell you that a field exists. A contract test shows you when and why that field matters.
For example, a schema might say that a status field is optional. A consumer, however, may rely on that field being present to drive business logic. Removing it may still pass schema validation—but it will break the consumer. Schema tests won’t catch this. Contract tests will.
This is why it is worth researching deeper whenever schema validation is being treated as “contract testing.” Without setting strong interaction expectations, teams are only validating grammar – not meaning.
Let’s understand how contract testing actually addresses this challenge in the real system.
It’s no surprise: Independent verification is the first principle. Instead of waiting for all services to be deployed and tested together, each service verifies its responsibilities independently.
This reduces feedback cycles and prevents late-stage surprises.
Your Consumer–provider contracts is the second principle.
The consumer states what it needs, and the provider ensures it can meet those needs. If both sides satisfy the same contract, integration should and will work as expected.
Backward compatibility protection is another critical upside that teams can get. Contract tests make it immediately visible when a change—such as removing a field or altering a response—will break existing consumers.
This helps teams to evolve APIs safely instead of relying on assumptions about “non-breaking changes.”
Finally, automation is essential. Contract tests are most effective when they run automatically as part of your CI/CD pipeline. Every change is validated against existing contracts, ensuring that breaking changes are caught early, when they are cheapest to fix.
For a large majority of testers and developers contract tests often feel like they don’t fit neatly into the traditional testing pyramid.
But that’s mostly because the pyramid was designed for monoliths, not for distributed systems.
In architecture systems we see now, contract tests act as the bridge between unit tests and integration tests. They reduce the need for excessive end-to-end testing while still providing strong system compatibility.
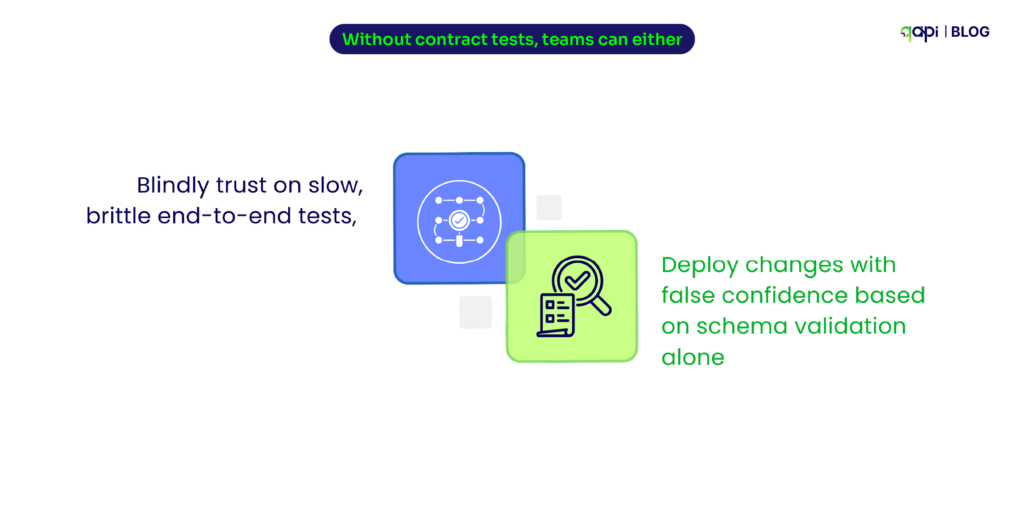
Without contract tests, teams can either:
• Blindly trust on slow, brittle end-to-end tests, or
• Deploy changes with false confidence based on schema validation alone
Neither of these options are good for business.
Contract testing is not about adding more tests. It is about reducing uncertainty.
When done well, contract tests allow teams to:
• Develop services in parallel without fear
• Detect breaking changes before integration
• Scale APIs without slowing delivery
In other words, contract tests exist to answer one simple but critical question:
“If this service changes today, who or what will it break tomorrow?”
Once teams understand that you will have no backlog and no burnout.
At a high level, contract testing follows a Consumer-Driven Contract (CDC) approach. This means the system that uses an API defines what it needs, and the system that provides the API proves it can meet those expectations.
Let’s walk through what this looks like step by step.
Everything starts with the consumer—because in distributed systems, breakage is always seen by the consumer first.
When you’re building Service A and it depends on Service B, you already have assumptions in your head:
• Which endpoint you’ll call
• Which fields you rely on
• Which response codes you handle
• Which error cases matter
Contract testing simply makes those assumptions clear.
From a developer’s perspective, this usually happens inside consumer tests. You write tests that simulate calling Service B, but instead of hitting a real service, you describe the interaction in a contract format—often as a pact file or schema-backed interaction definition.
This contract includes:
• The HTTP method and endpoint
• Required headers or auth behavior
Example request payloads
• Expected response status codes
• Required response fields and their meanings
At this stage, you are not testing whether Service B actually works. You are documenting what you expect it to do.
Once these consumer tests run, they generate a contract which is usually a machine-readable file that describes the expected interactions.
This file can prove everything. It is sent to a contract repository or broker that both teams can access. Importantly, this happens automatically as part of the consumer’s CI pipeline.
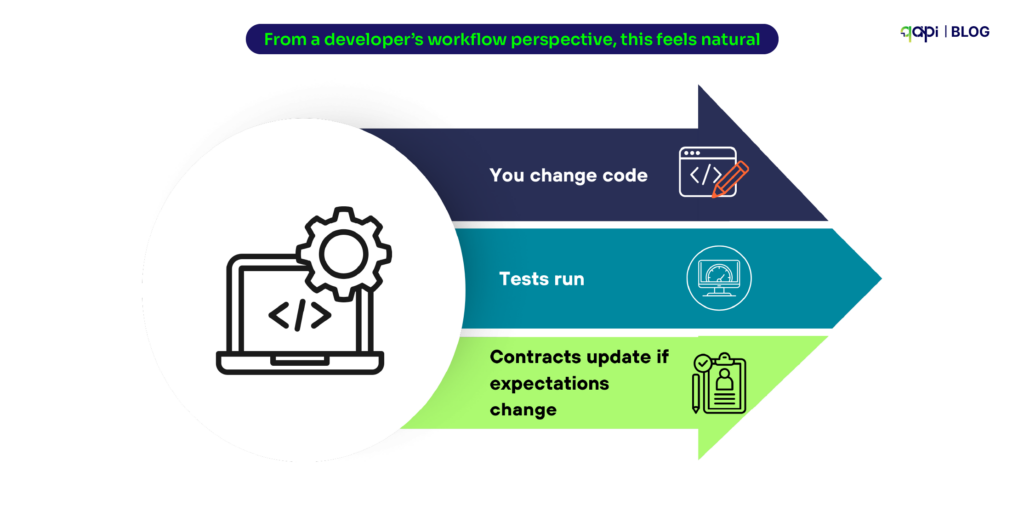
From a developer’s workflow perspective, this feels natural:
• You change code
• Tests run
• Contracts update if expectations change
If you intentionally modify how you use an API.
For example, let’s say you start relying on a new field—that change is reflected immediately in the contract.
No meetings, no emails, but you have results.
Now the responsibility shifts to the provider.
When service B pulls the published contracts and runs provider verification tests, these tests check whether the provider can satisfy every contract that consumers can depend on.
If the provider passes verification:
• It has proven that it still supports all existing consumers
• It is safe to deploy from a contract perspective
If verification fails, it means something meaningful:
• A field was removed
• A response code changed
• Behavior no longer matches expectations
At this point, developers have clear options:
• Fix the provider to restore compatibility
• Update the consumer and version the API
• Introduce backward compatibility logic
The failure is early, isolated, and actionable—which is exactly what you want.
One of the biggest advantages of contract testing is how cleanly it handles mismatches.
Instead of discovering breakage during integration or production testing, teams can respond deliberately:
• Providers can introduce non-breaking extensions
• Breaking changes can be gated behind new API versions
• Consumers can migrate incrementally
This turns API evolution into a controlled process instead of a risky guessing game.
Real systems don’t stand still, and contract testing supports that reality well.
When APIs grow, contracts can be versioned alongside code. Older contracts remain valid until consumers migrate, while new contracts define new behavior. Providers can support multiple versions simultaneously and verify compatibility independently.
Feature flags add another layer of safety. New behavior can be introduced behind a flag, with contracts clearly written for that path. Once consumers are ready, the flag can be rolled out confidently—knowing the contract has already been validated.
It’s all about reducing risk without reducing speed. As it allows you to:
• Refactor APIs safely
• Deploy independently
• Avoid breaking consumers you don’t even know exist
• Replace guesswork with executable agreements
When contract testing is in place, API changes stop being scary. They become routine, predictable, and boring—in the best possible way.
Isnt’ that what you and your team needs?
And now, the testing industry needs to take the next logical step: Letting a smart tool to fill the gap.
qAPI removes the manual work from contract testing. That means you don’t have fuss about the work needed for running tests, qAPI can provide all that and support 24×7 for all your API testing needs
With qAPI, teams can:
• Generate contracts directly from OpenAPI specs
• Auto-create contract tests for requests and responses
• Validate schema changes on every build
• Run contract tests in CI/CD without writing code
• Share contracts across teams in one workspace
When a change breaks the contract, qAPI flags it instantly—before it reaches production. So have complete visibility on what’s happening, less doubt and more confidence. It’s easy to be a skeptic, there’s so much to care and figure out about: API privacy, data safety and what not.
After all, the stakes are always high, it’s just the technicality that’s overly bloated contract testing is necessary and it can be a cakewalk without any serious implications.
You can take care of your APIs and contract tests all one place with qAPI.
It’s the same story with every company starting out or a older one that’s attempting to restructure their processes. They have a problem choosing the ideal QA test management platform.
Every CTO and tech team now claims to be agile and completely on cloud, but the real problem isn’t technology it’s about how companies approach using it. In the last few months, we have worked with leaders and teams who didn’t experiment but still managed to scale.
Why? Because they were able to make bets based on the decisions they made on what they wanted to achieve and how. Across any vertical, be it healthcare, IT, or manufacturing, there was a common pattern. Teams got lean and simplified their API testing process, which took transformation seriously and decided to use tools that simplify rather than complicate.
The teams that get this right follow one principle: simplify first, automate second.
Here are some lessons from those who managed to scale after choosing qAPI for their QA test management platform.
Test Management Platform is all about where you handle your software testing needs for planning, testing, and monitoring the testing activities, which will be finally used for product quality and assurance.
As a test management platform, QA teams expect a way to get things streamlined and move faster along the entire software development lifecycle. The goal here is to find issues and implement their fixes.
But here’s where most teams get stuck: They implement a tool that just adds another layer of complexity. The magic happens when your test management platform becomes the quality intelligence layer that makes Jira smarter about what “done” really means.
You will get the following answers
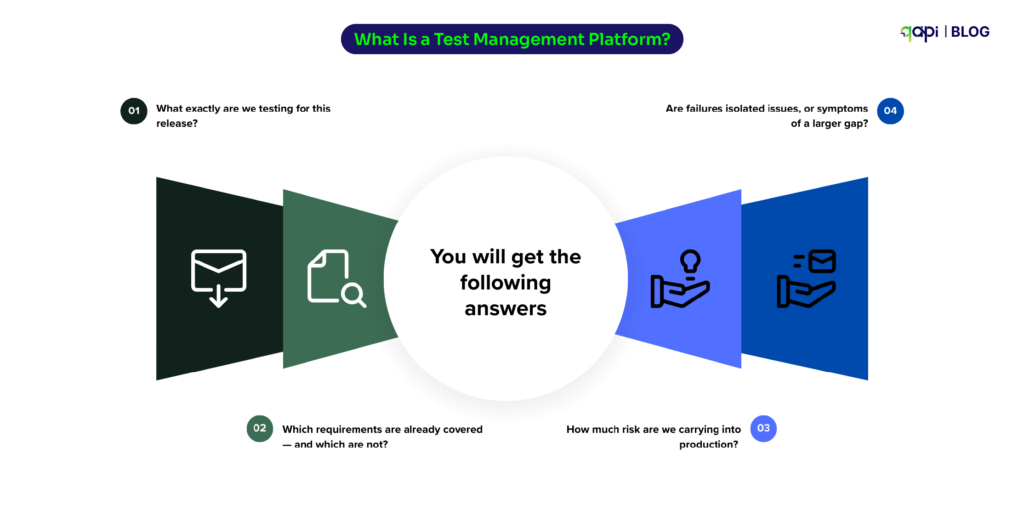
• What exactly are we testing for this release?
• Which requirements are already covered — and which are not?
• How much risk are we carrying into production?
• Are failures isolated issues, or symptoms of a larger gap?
Now that you know how a test management tool works and what its purpose is, let’s clear the air by showing how different it is from a test automation tool.
What Test Automation Tools Actually Do
Test automation is the practice of using software tools and scripts to automatically execute tests, validate outcomes, and report results. Instead of a tester repeatedly clicking through the same workflows, an automated test completes those checks automatically by checking that an application is working as expected after every code change.
These automation frameworks are designed to:
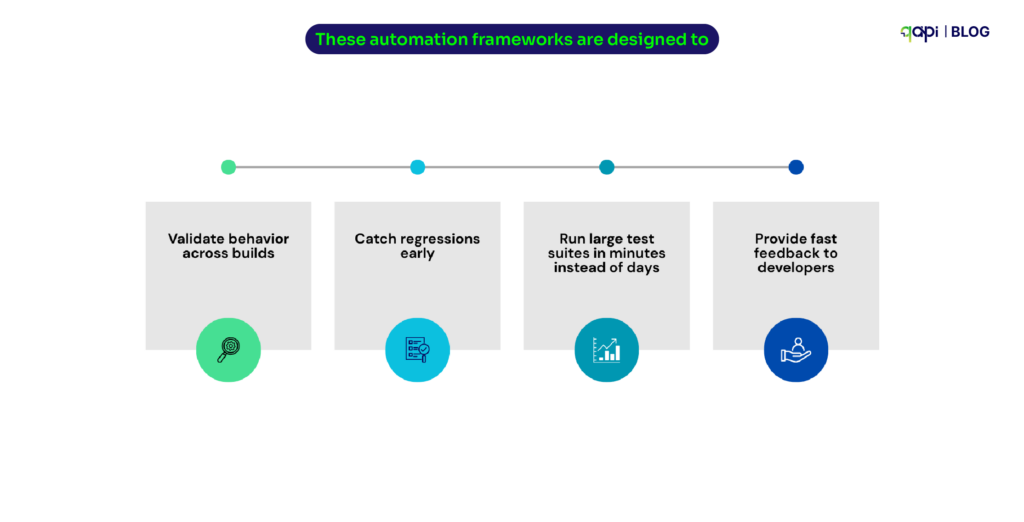
• Validate behavior across builds
• Catch regressions early
• Run large test suites in minutes instead of days
• Provide fast feedback to developers
When these tools are properly connected, the workflow becomes much simpler — and much calmer.
Here’s how high-performing teams should operate:
1️⃣ Plan and prioritize in the test management platform. List down requirements, risks, and test scope.
2️⃣ Execute via automation as automation frameworks run tests continuously through CI/CD.
3️⃣ Sync results automatically as test results flow back into the management platform in real time.
4️⃣Analyze impact as it will help teams to see which features are affected, what’s still untested, and where risk is concentrated.
5️⃣ Decide with confidence based on the impact you must decide the next step. Go / no-go decisions are based on coverage and impact.
Important Features of a Modern Test Management Platform
is no longer a nice-to-have — it’s essential. Because so many engineering organizations use Jira as their central project hub, a test management platform must sync bi-directionally with Jira issues so that updates to requirements, defects, and tests flow seamlessly across tools.
• Employees using more than 10 apps report communication issues at 54%, versus 34% for those using fewer than 5 apps, showing how tool fragmentation directly harms coordination.
• A Deloitte-cited study found that organizations that improve collaboration and streamline how people work see around 40% improvement in project turnaround times, largely by reducing status-chasing and rework.
A core capability that lets teams map tests to features and defects. When test cases are directly linked to user stories and bugs, it’s possible to see coverage at a glance — not just raw pass/fail counts.
This traceability is a major helper between a simple test case repository and a true quality command center. An IEEE study showed that more complete requirements traceability correlates with a lower expected defect rate in the delivered software, providing empirical evidence that traceability boosts quality.
Where manual and automated test outcomes appear together is also essential. In the absence of a single view, teams waste time switching between tools and adding data manually.
With such dashboards, when data flows in real time, stakeholders can understand quality trends, identify regressions early, and make data-driven decisions rather than relying on intuition and educated guesses.
Why do we say that because people will spend less time assembling reports and more time acting on them. Businesses that promote strong collaboration and shared visibility are up to five times more likely to be high-performing.
As your test suites evolve, teams will change, and codebases will shift, it’s critical to know not just what changed but also why and when. Version history lets teams audit the evolution of tests, understand test maintenance impact, and prevent regressions caused by untracked edits. Without this, test suites will drift and you will lose trust over time.
Role-based collaboration is another key feature. Different stakeholders interact with quality data in different ways: developers need technical detail, QA teams want execution context, and product owners want high-level coverage and risk metrics. Platforms that allow tailored views and permissions help teams work together without confusion or noise.
Especially for teams aiming to scale, cloud-native architecture is vital. Legacy on-premises test management systems can become a huge problem under heavy workloads, whereas cloud platforms scale elastically, reduce administrative overhead, and support distributed teams working across geographies and pipelines.
In practice, when these foundational features are in place, teams start to experience measurable improvements in efficiency and visibility. With qAPI test management isn’t about collecting test cases — it’s about turning testing data into insight and predictable outcomes. If a platform can’t offer these core capabilities, then your exposed to risks and achieving nothing more than a digital notebook rather than a strategic quality partner.
Yes, and with qAPI, it is built-in.
In a traditional setup, you might struggle to connect a test management tool with separate automation scripts (like Selenium) and a CI server. But with qAPI, this integration is seamless because the platform handles both the execution and the management of tests.
• Capturing and Reporting Results: Instead of needing a third-party plugin to “fetch” results, qAPI provides real-time reporting natively. Whether you are running a functional API test or a load test, the results (pass/fail status, latency, payload data) are instantly visible in the qAPI dashboard.
• Workflow Integration (CI/CD): qAPI is designed to fit into your existing DevOps pipeline. It offers native integrations and webhooks for tools like Jenkins, Azure DevOps, and GitHub Actions.
The Workflow: When your CI pipeline triggers a qAPI test suite via a simple cURL command or plugin → qAPI executes the tests in the cloud → Results are sent back to the pipeline to either pass the build or stop it if bugs are found.
• What “Automation Support” Looks Like in qAPI: It means you don’t have to context-switch. You can view your test execution history, analyze failure logs, and manage your test data (CSV/Excel) all within the same interface where you built the automation.
When moving to an intelligent platform like qAPI, ROI isn’t just about saving money—it’s about velocity and risk reduction.
• Faster Release Cycles: With features like AutoMap, teams can reduce test creation time by up to 50%. Instead of manually stitching workflows together, qAPI automates the connections.
• Reduced Manual Overhead (Efficiency): qAPI’s no-code/low-code interface allows manual testers and business analysts to contribute to automation. This removes the bottleneck of relying solely on SDETs for every single test script.
• Infrastructure Savings (Cost): With Virtual User Balance (VUB), you only pay for the load you generate. There is no need to maintain expensive, idle servers for load testing.
We often see small teams often thinking they are stuck with open-source tools that require heavy setup and maintenance (like hosting your own server) because enterprise tools are too expensive. qAPI as a B2C tool bridges this gap.
• Low Barrier to Entry: qAPI is cloud-native (SaaS). A small team can sign up and start testing immediately without needing to install servers or configure complex databases.
• All-in-One Capability: Small teams rarely have the budget for three separate tools (one for functional testing, one for load testing, and one for reporting). qAPI offers Functional, Load, and Reporting in a single license, making it a cost-effective powerhouse for lean teams.
• Scalability: You can start small with functional testing and, as your user base grows, instantly scale up to load testing using the same scripts you already wrote.
In 2026, a test management platform can’t just be a place to store test cases. It needs to act as the command center for your entire automation strategy.
The line between managing tests and executing them is disappearing. Teams no longer have the patience—or the budget—for stacks that require stitching together plugins, maintaining brittle Selenium glue code, or running load tests on completely separate infrastructure. That model simply doesn’t scale.
1️⃣ Consolidation drives real ROI The highest-performing teams reduce tool sprawl, not expand it. Platforms like qAPI, which bring functional validation, load testing, and reporting into a single workflow, eliminate context switching and operational drag. Fewer tools mean faster feedback—and faster releases.
2️⃣ Automation should be native, not bolted on Automation only works when it fits naturally into your pipeline. Look for platforms that plug directly into CI/CD systems like Jenkins and GitHub Actions, without requiring custom scripts or fragile integrations. If automation feels like extra work, adoption will stall.
3️⃣ ROI must be provable, not assumed Modern QA leaders don’t justify tools with intuition. They use metrics. Time saved through automated mapping, reduced infrastructure costs via on-demand virtual users, and faster release cycles all translate directly into business impact.
Before committing to any tool, ask yourself:
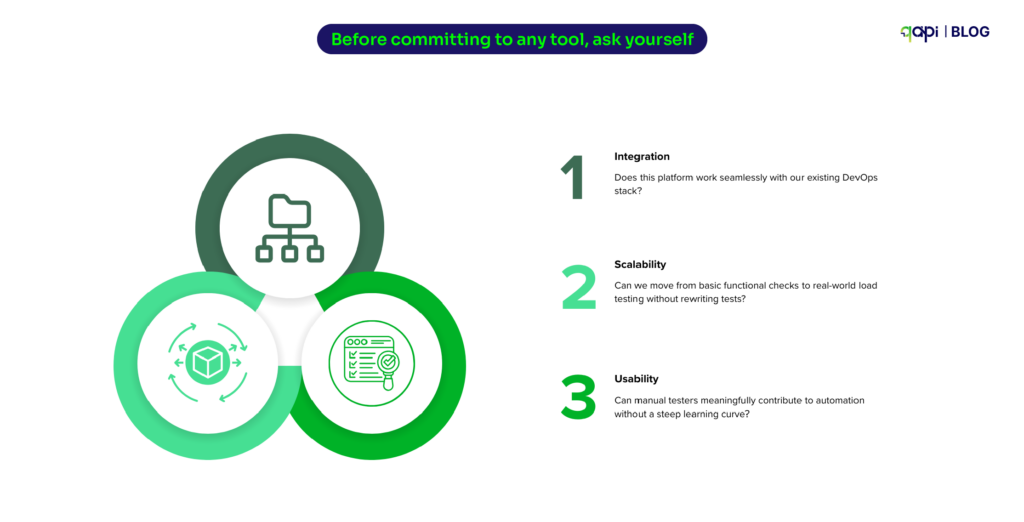
• Integration: Does this platform work seamlessly with our existing DevOps stack?
• Scalability: Can we move from basic functional checks to real-world load testing without rewriting tests?
• Usability: Can manual testers meaningfully contribute to automation without a steep learning curve?
If the answer isn’t “yes” across all three, the platform will become a bottleneck.
The Bottom Line
The future of test management isn’t about managing more artifacts. It’s about building and managing with quality and fewer problems.
If your current setup feels too cluttered, slow, or overly complex, it may be time to rethink the foundation. qAPI, as an API test management platform, doesn’t just improve testing—it’s redefining how teams are shipping software.
A note from Raoul Kumar, Director of Platform Development & Success, Qyrus
As this year comes to a close, I want to begin with a simple but heartfelt thank you.
To every tester, developer, and team that chose qAPI—tried it, challenged it, broke it, and helped shape it—this journey would not have been possible without you. 2025 was not just a year of shipping features. It was a year of listening deeply, questioning assumptions, and doubling down on what truly matters: helping teams test APIs with confidence, clarity, and speed—without friction.
This is our look back at what we built, why we built it, and what the world of real testing taught us along the way.
Here’s to everything we learned in 2025—and to an even stronger 2026 ahead.
We’ve been testers. We’ve seen the frustration of juggling tools that weren’t designed for QA teams.
We’ve seen how API testing was often treated as an afterthought — complex, code-heavy, and disconnected from real business flows.
So we asked a simple but powerful question: What if API testing actually worked the way testers think?
Not just functional checks. Not just scripts. But end-to-end confidence — from functional to process to performance — all in one place.
That question became qAPI.
We started the year by asking ourselves a hard question:
Is qAPI truly aligned with how teams test APIs today—or how they need to test them tomorrow?
That insight led directly to the qAPI rebrand and UI refresh. We had decided then that the goal wasn’t just to improve UI/UX. It was go a step ahead and make an easy to use and seamless.
To answer that we began with one of the largest internal, cross-functional gatherings we’ve ever had. Engineering, product, sales, marketing, and customer teams came together with one shared goal: to deeply understand how qAPI fits into real testing workflows — and how it could do even more.
It was a session to show how the new platform works end-to-end, how no-code automation can remove barriers for testers, how developers can move faster without sacrificing quality, and how organizations can eliminate manual overhead without losing control.

We answered several questions, gave a live demo, and helped our teams understand and get used to the qAPI application. With this, we got the push we needed as the word spread internally and to other folks in the testing space.
It worked in our favour because-
As teams globally started running their API tests with qAPI, we saw a different kind of problem that they faced.
Tests existed, but teams didn’t always trust them. Failures were sometimes caused by timing issues, shared environments, unstable data, or inconsistent API responses rather than real regressions.
This created a problematic situation for teams, as they either ignored failures or spent too much time trying to determine whether a test was lying. At this stage, we realized we needed to solve this so teams could gain predictability and structure.
This is where our development team shifted focus toward improving how teams manage environments, validate responses, and maintain consistency across APIs. So that APIs can have clear response structures, better handling of test data, and cleaner separation between environments, which helped reduce noise and make failures meaningful again.
Read more about Shared workspaces.
Around this time, we also released the Beautify feature in qAPI. It may seem small, but it addressed a real pain: the code developers write is mostly messy/hard to read. Whether you’re testing APIs or preparing to deploy, beautify ensures your code is always clean and structured.
In the next few months we saw a growing concern around reliability, users asking questions like: “This API works but how to check it’s limitations?” “Will the API be stable and work under real traffic?”
When we interacted with testers and other users, they told us
That they wanted a way to flood the service with multiple requests and test it to identify any lapse in performance under load. But because current load testing methods felt disconnected—heavy tools, separate workflows, and long setup times. Our teams decided to solve this by creating a pay-as-you-go load testing feature update Virtual User Balance (VUB).
The goal was never to replace performance engineering. It was to close the gap between correctness and scale—so teams could catch performance issues before they reached production.
We gave away free 500 virtual users no questions asked just to get the ball rolling!
Next, we also hosted a webinar to address the misconceptions holding teams back. In our session, “Debunking the Myths of API Testing,” we removed the confusion surrounding API quality—challenging the persistent ideas that it is too complex, requires heavy coding, or is secondary to UI testing. By breaking down these barriers, we demonstrated how qAPI , an end-to-end API testing tool can make API testing accessible and essential for early bug detection, empowering teams to shift left with confidence.
Watch the Webinar Here
APIs Moved to the Center Stage
At API World (September 3–5), APIdays London (September 22–25), StarWest (September 23–25), and APIdays India (October 8–9) We had some interesting conversations with engineering leaders who described their problems.
We used those problem statements to demonstrate the power of qAPI. By showing attendees how they can execute end-to-end tests—seamlessly transitioning from functional, process to performance load within a single interface—we proved that you don’t need a complex, disjointed toolchain to build scalable APIs.
A snippet from API world
Raoul Kumar took the stage twice—first with a hands-on workshop on using agentic orchestration to test APIs, and later with a keynote that explored the future of API testing through a no-code, cloud-first lens.
At APIdays India, Ameet Deshpande gave a talk that really resonated with the crowd. He explained why old ways of testing just can’t keep up with today’s complex, AI-powered world. He stated that we need smarter, AI-led tools to manage the workload. The next day, Ameet hosted a workshop along with Punit Gupta, where attendees saw qAPI in action. They learned how using AI “agents” to run tests can help them check much more of their software and ship it faster.
These conversations directly influenced our push toward shared workspaces in qAPI, enabling teams to collaborate, manage environments, and scale testing together — rather than working in disconnected groups.
With this update teams can now easily view and make changes in dedicated environments and the other involved teammates can directly access the updated APIs without having to check with each other and get the updated dataset.
Developers at the Center
APIdays India, Bengaluru – Oct 8–9
India’s scale demands a different approach to quality. Through talks and hands-on workshops, Qyrus demonstrated how agentic orchestration can dramatically expand API test coverage without slowing delivery.

Our team spent two energizing days connecting with developers, QA leaders, and digital architects who are building API-first systems for one of the world’s fastest-growing digital economies. Ameet Deshpande’s talk on why API testing needs to change struck a strong chord, highlighting how traditional QA struggles in AI-driven, highly connected ecosystems, and why agentic orchestration and multimodal testing are becoming essential.
That thinking came to life during a packed, hands-on workshop with Ameet and Punit Gupta, where attendees saw firsthand how directing AI agents can dramatically expand API test coverage and accelerate delivery.
HackCBS 8.0, New Delhi – Nov 8–9
We partnered with India’s largest student-run hackathon reminded us why accessibility matters. Students embraced API testing as an enabler — validating ideas faster and building with confidence from day one.
Being surrounded by thousands of passionate student builders, innovators, and problem-solvers was a powerful reminder of why quality and experimentation matter from day one.
Through hands-on workshops led by Punit Gupta and engaging conversations at our booth, we introduced qAPI as a practical, developer-friendly way to test and validate prototypes faster without slowing creativity. What stood out most was the curiosity and confidence with which students approached API testing, asking thoughtful questions and immediately applying what they learned to their ideas.
Before we ended the year, we added a few more updates!
Import via cURL
Developers already use cURL to debug APIs. Turning that into an automated test used to mean manual rework. With Import via cURL, a working command becomes a test in seconds—closing the gap between manual checks and automation.
Expanded Code Snippets
By adding C# (HttpClient) and cURL snippets, testers and developers can now share executable logic—not screenshots or assumptions. Testing feeds development instead of running parallel to it.
AI Summaries
As workflows grow complex, understanding why a test exists becomes harder than running it. AI Summaries make tests readable, explainable, and safer to maintain—especially during onboarding and incident reviews.
As we step back and look at everything that unfolded over the year—the product decisions we made, the conversations we had across global stages, and the feedback we heard directly from developers and testers—a clear pattern emerges. Each update solved the problems we’d seen repeatedly — in conversations, workshops, and real customer workflows.

Over the past year, qAPI has grown from an API testing tool into a platform teams rely on every day—across development, QA, and delivery—to move faster with confidence. What started as a way to simplify API testing has evolved into something much bigger: a system that helps teams design better APIs, test earlier, collaborate more effectively, and trust their releases in increasingly complex environments.
As we look ahead, the ambition only grows. The coming year will bring deeper intelligence, tighter workflows, and even more ways for developers and testers to work in sync—without friction, without guesswork, and without compromising quality.
Thank you for building with us, challenging us, and shaping qAPI along the way. There’s a lot more coming—and we’re just getting started.
If there’s one thing developers, testers, and SDETs will agree on in 2026, it’s this: API automation is no longer optional.
A API automating testing strategy is a plan that ensures the speed and reliability of your APIs , the goal is to identify high-intent issues that are most likely to hurt once the team and application grows. Whether you’re building microservices, mobile apps, or enterprise backend systems, automating your API testing process will be the most promising move you make and help you clear issues much faster.
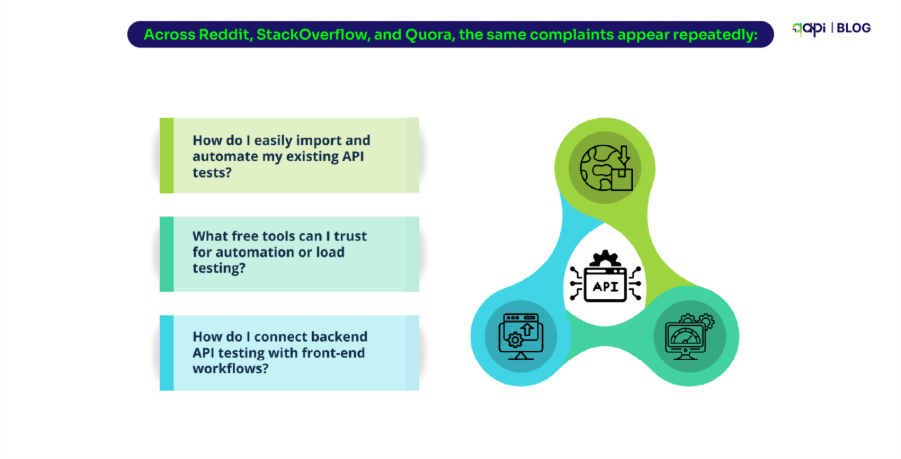
Across Reddit, StackOverflow, and Quora, the same complaints appear repeatedly:
• “How do I easily import and automate my existing API tests?”
• “What free tools can I trust for automation or load testing?”
• “How do I connect backend API testing with front-end workflows?”
This guide answers those exact questions — with real forum insights, practical workflows, tool comparisons, and how qAPI fits into modern testing stacks.
On Reddit’s r/softwaretesting, a user recently posted: “My team spends 30% of every sprint manually testing the same API endpoints. We’re moving slow and still finding bugs in production. Is this normal?”
The answer is: it’s common, but it’s not normal.
What users get wrong is that API automation isn’t just about “testing faster.” It’s about building a safety net that allows your team to work efficiently.
One Quora answer explains it best:
• Manual API testing = exploratory, ad hoc
• API automation = consistent, repeatable, CI/CD-friendly
This distinction matters because teams that rely only on manual tests are shipping blind. If we compare it to the release velocity teams globally are working towards, that’s a deal-breaker.
The transition from manual-heavy testing to API-first automation isn’t just a surfacing now; it’s a response to deep architectural and workflow changes happening across the software industry for more than a decade.
1️⃣ Microservices Usage are Exploding
Current systems we develop and use are no longer monolithic. They’re divided into dozens or hundreds of microservices, and every service exposes multiple APIs. Which clearly means:
More endpoints, More integrations, More dependencies, More failure points
A single release can impact 15–30 upstream or downstream services — something manual testing cannot reliably validate. So, it’s just poetic that API testing automation becomes the only scalable way to maintain confidence across distributed systems.
2️⃣ CI/CD Pipelines Demand Fast, Stable Feedback
Companies are moving toward high-frequency deployments, and CI/CD pipelines expect tests to run faster without any human intervention.
Manual API tests simply do not fit into the CI/CD loop.
3️⃣ AI-Generated Code Introduces New Types of Hidden Risk
With Copilot, Replit AI, Lovable, and LLM-based code generation tools everywhere, teams are shipping more code, faster — but not always more reliable code.
AI-generated functions often introduce:
• unhandled edge cases
• silent schema drift
• subtle regressions
• missing validation logic
Without an API testing automation tool, these issues will show up late in QA or worse — in production.
4️⃣UI Tests Can’t Handle Modern Complexity
Teams everywhere have learned the hard way that relying on UI tests for backend validation leads to slow execution and late-stage bug discovery.
As systems become more distributed, UI tests reveal symptoms, not root causes. API tests go deeper by validating logic at the source, reducing the cost and complexity of debugging.
Performance testing is one of the most searched API topics on Reddit’s r/devops and r/softwaretesting.
We saw the recurring questions:
❓ “How do I simulate 1k–50k virtual users?”
❓ “What’s the best way to integrate load tests into CI/CD?”
❓ “How do I track p95 / p99 latency under heavy traffic?”
Traditional vs Modern Load Testing
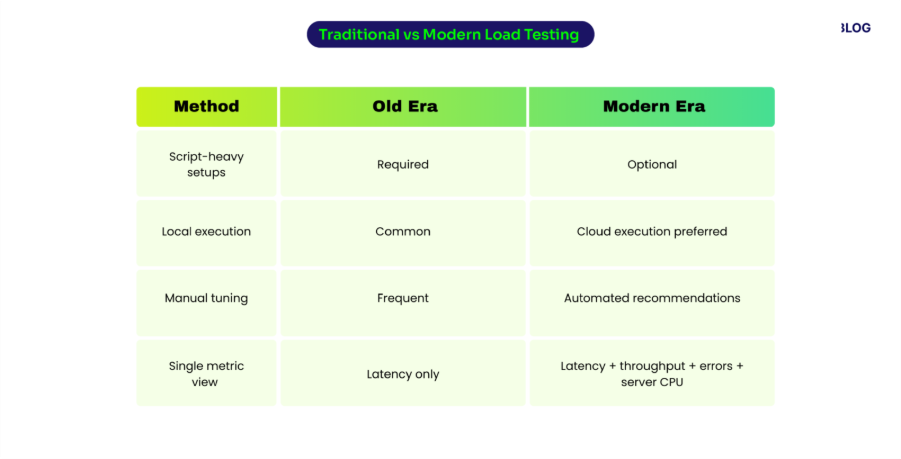
Users often confuse peak vs spike load (a top-ranking question on multiple forums).
• Peak load = sustained high traffic
• Spike load = sudden unexpected traffic burst
Load testing is no longer optional— it’s essential for mobile-heavy APIs, fintech apps, e-commerce, and B2B SaaS workflows.
When teams search for the best import API testing tools for software testing, they’re all looking for the same thing: “How do I move fast without rebuilding everything from scratch?”
And honestly, that’s the biggest psychological barrier in API automation today.
You’ll see it everywhere on Reddit, Slack groups, and testing forums — people frustrated because they’ve already built hundreds of requests inside Postman, Swagger, or cURL… and now every “new tool” expects them to rebuild those tests manually.
That’s not just tedious. It’s demotivating. It’s why so many teams delay automation for months.
Import-based automation tool qAPI eliminates that.
Currently, teams don’t have the time and bandwidth to start from zero. They need automation now — and the fastest path is through smart importing.
“How do I import Postman or Swagger collections directly into my automation tool?”
This is the #1 question asked across Quora, Reddit, and Stack Overflow.
Today’s API automation testing tools come with native import support. You upload a Postman file, OpenAPI spec, Swagger doc, or even a cURL snippet — and the tool instantly generates your test suite.
“Can I re-use existing API tests without manual reconfiguration?”
This is where great tools stand apart from the merely “popular import API testing tools.”
Basic import = list of endpoints. Smart import = usable, runnable workflows.
Because qAPI can:
• Detect environment variables
• Identify authentication flows
• Chain dependent requests
• Build functional workflows automatically
This is why testers say importing API specs cuts setup time by up to 60%.
And that’s why qAPI’s import features are now the defining safeguards of the best import API testing tools for software testing.
Importing clubbed along with Automation it’s what makes large-scale API automation realistic for small and large teams alike.
A smart import system will help you:
• Launch automation in hours, not months
• Avoid rewriting years of Postman work
• Maintain consistent test coverage across microservices
• Accelerate regression testing
• Automatically support CI/CD pipelines
For busy QA teams, this is the difference between falling behind releases and being ahead of them.
Every pain point testers mention online led to a specific design choice in modern platforms — especially unified, smart-import tools. Here are some of the major one’s that will help you out.
Pain Point #1: “I’m a manual QA, and I don’t know how to code.”
Many subscribers say this is what stops them from trying automation.
The Solution: Use a 100% no-code visual builder where workflows feel more like user journeys than scripts. If you can describe a scenario, you can automate it.
Pain Point #2: “We have years of Postman collections. Migration will take forever.”
This is the fear that blocks API automation from even starting.
The Solution, Import everything in qAPI:
• Postman
• OpenAPI
• Swagger
• cURL
• JSON definitions
AI converts those imports into clean, maintainable workflows — in minutes, not weeks.
Pain Point #3: “We use one tool for functional tests and another for load tests.”
This fragmentation is one of the most common frustrations in online communities.
The Solution: qAPI is a unified platform where you can:
1️⃣ Build a functional test
2️⃣ Add virtual users
3️⃣ Instantly turn it into a load test
One workflow. Multiple testing modes. Zero duplication.
This solves a major market gap that current tools miss and aligns perfectly with how fast paced engineering teams work.
If you’re a QA lead, tester, or developer, here’s the real benefit:
You finally get time back. You finally get clarity. You finally get automation that feels doable, not daunting.
With qAPI the Import capabilities remove the intimidation factor from API automation. Unified workflows eliminate juggling multiple tools. And the No-code features remove the fear of getting left behind.
This is why testers today look specifically for:
• API automation testing tools with strong import support
• Popular import API testing tools that reduce setup time
• API load testing methods that reuse the same workflows
Free import API testing tools for software testing to get started quickly
The industry is shifting. Tools are evolving. So is qAPI to help with your growing needs And teams that adopt import-first automation gain speed, consistency, and quality — all without burning out their testers.
Based on Reddit threads and user conversations, qAPI stands out for solving:
1️⃣ No-code automation workflows
Testers without scripting expertise can automate and build end-to-end flows.
2️⃣ Full import support
Postman, Swagger, OpenAPI, Insomnia, cURL — all in one platform.
3️⃣ Integrated load testing
You can start with free virtual users, analyze p95/p99 latency, and correlate client and server metrics. You can refine your testing further by adding as many virtual users as you can.
4️⃣ AI assistance
Generate tests, validate responses, detect missing parameters, catch schema drift.
5️⃣ Unified dashboards
Automation + load + regression all in one place. Users get detailed information for each and every test they run helping them understand the API performance stretched over a period of time.
Here’s what the teams in API landscape in 2025 demand for:
• Faster releases
• Scalable automation
• Powerful load testing
• Seamless imports
• AI-assisted efficiency
Whether you’re migrating Postman suites, handling high-traffic microservices, or scaling test automation across teams, qAPI unifies everything — import, automation, load, and AI — in a single platform.
It’s built for testers who want to do more with less friction. It’s built for devs who want CI/CD-ready pipelines. It’s built for teams who want a true API-first testing strategy.
1️⃣ How do I automate API regression tests using Postman imports?
Import your Postman collection → auto-generate test suites → configure assertions → schedule runs in CI/CD. qAPI supports this.
2️⃣ Are AI-based API automation helpers reliable?
AI-based assistants excel at generating tests, identifying missing assertions and detecting schema changes. They’re not perfect, but with qAPI, you can drastically reduce manual effort.
3️⃣ How do I troubleshoot flaky API load tests?
Check dynamic parameters, rate limiting, server throttling and environment instability. qAPI can visually correlate error spikes with server metrics to isolate root causes faster.
4️⃣ How do I schedule imported API tests in CI/CD pipelines?
Two options:
• CLI/automation runner tools
• Native CI plugins (GitHub Actions, GitLab, Jenkins)
Most modern AI-driven platforms, including qAPI, provide both.