
Large Language Models (LLMs) are everywhere and now in 2026 we don’t think you can survive the tech space without knowing a tool or two that runs on AI. The AI led tech is now powering customer support chatbots, code assistants, content generation, legal research, medical summarization, and more.
But here’s the problem with it. With evaluation news dominating headlines and new benchmarks dropping almost weekly with models like ChatGPT, Minimax and Claude 4 etc creating and pushing new boundaries, and enterprises quietly panicking about hallucinations in production.
Because they are unable to choose the best pick for their product, as there are a lot of failures and guesswork that you’d probably don’t want to deal with. Let’s just say for a new mobile application you wouldn’t ship the app without performance testing, security scans, and real-user simulation. Yet thousands of teams are deploying Large Language Models in customer-facing tools, virtual AI assistants, and decision systems with little more than a gut feeling and a few cherry-picked examples.
This guide breaks down exactly what an LLM evaluator is, why the industry is suddenly obsessed with LLM evaluation, and how platforms like qAPI are making it easier to handle it.
Let’s dive in.
So, What Are LLM Tools, Really?
At it’s core, LLM tools are platforms, frameworks, or APIs that let you harness large language models for real work: generating content, answering questions, summarizing documents, classifying text, writing code, extracting entities, and more.

Popular examples include:
- OpenAI’s GPT series (via API)
- Anthropic’s Claude
- Minimax
- Google’s Gemini
- X AI’s Grok
and the list goes on.
These tools usually expose a simple text-in/text-out interface, but underneath they’re massive statistical pattern matchers trained on trillions of tokens.
What is an LLM Evaluator?
An LLM evaluator is a framework designed to measure the capabilities how good (or bad) a large language model performs on specific tasks, datasets, prompts, or real-world use cases.
It’s not like traditional software testing (where outputs are deterministic), LLM evaluation deals with probabilistic, generative systems — so you’re not just checking correctness, but also:
– Faithfulness — does the answer stick to provided context / facts?
– Relevance — is it actually answering the question asked?
– Safety — does it avoid harmful, toxic, or jailbreak content?
– Consistency — same prompt → reasonably similar answers over time?
– Helpfulness / Coherence — is the tone, structure, and depth appropriate?
– Authenticity — is factual information supported by sources?
– Efficiency — latency, token cost, throughput under load
So How to Pick the Best LLM Tool

Step 1 – Pre-Deployment: Define Decision Criticality
You need to understand that not every LLM use case carries the same risk weight.
A content-summarization assistant for internal memos is not the same as an LLM that recommends credit limits, flags suspicious transactions, or drafts regulatory disclosures. The first step in any enterprise evaluation program is to map the AI use case against a decision criticality framework.
Decision criticality is determined by three factors:
• Reversibility — Can a wrong answer be caught and corrected before harm occurs?
• Regulatory exposure — Does the domain fall under consumer protection, fair lending, data privacy, or financial crime rules?
• Downstream consequence at scale — What happens if systematic error affects thousands or millions of decisions?
Quick mapping of common enterprise use cases:
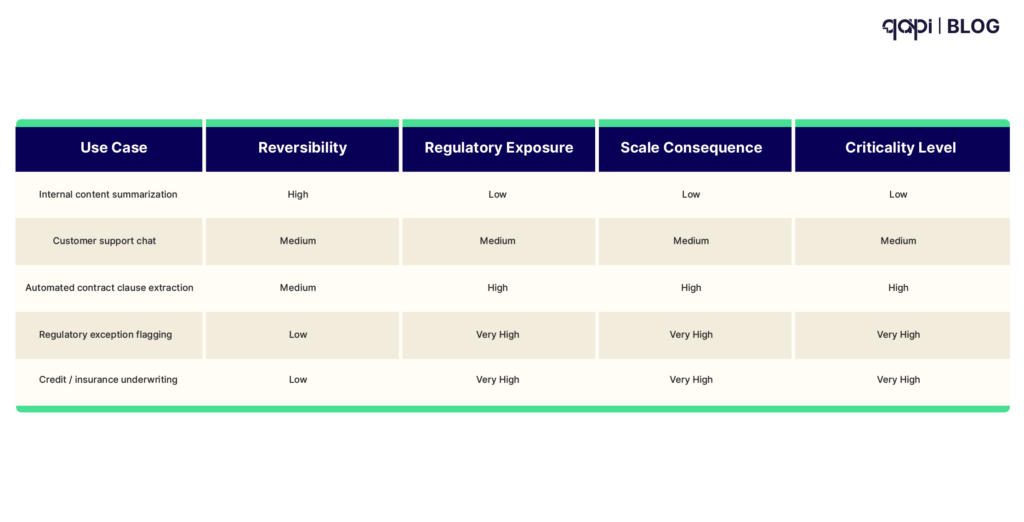
AI Use Case Risk & Criticality Matrix
| Use Case | Reversibility | Regulatory Exposure | Scale Consequence | Criticality Level |
|---|---|---|---|---|
| Internal content summarization | High | Low | Low | Low |
| Customer support chat | Medium | Medium | Medium | Medium |
| Automated contract clause extraction | Medium | High | High | High |
| Regulatory exception flagging | Low | Very High | Very High | Critical |
| Credit / insurance underwriting | Low | Very High | Very High | Critical |
What you need to keep in check here is that every proposed LLM use case has to be scored against this framework before any pilot begins.
High-criticality and critical applications must have mandatory human-in-the-loop review gates, full audit trails, and documented evaluation protocols before production deployment is approved.
Step 2 – Stress-Test for Hallucinations & Bias
Hallucination is one of the top #1 operational risk in decision-critical LLM deployments.
When an LLM confidently cites a non-existent regulation, invents a clinical contradiction, or applies an incorrect factor, it does not raise a red flag.
It simply continues. Gartner notes that organizational data not seen during training often exposes quality collapse exactly where high-stakes decisions are made.
Gartner clients have reported that when organizational data not accessible during LLM training is introduced, model responses are often not of benchmarked quality. [1] This is precisely the condition under which high-criticality decisions are made.
Stress-testing must cover three dimensions:
• Factual accuracy — Does the model anchor answers to verifiable, retrievable sources, or does it confabulate from statistical patterns?
• Demographic bias — Do outputs vary systematically across protected characteristics in ways that create discriminatory outcomes?
• Adversarial robustness — Does behavior remain stable under edge-case inputs, prompt injection, jailbreak attempts, or semantically ambiguous queries?
For credit, lending, insurance, and regulatory reporting applications, bias testing is not optional—it is legally required under the Equal Credit Opportunity Act, Fair Housing Act, GDPR fairness principles, and equivalent frameworks globally.
qAPI Suggests: Create a rule to document bias and hallucination testing methodology and results as part of the compliance audit record. Use multiple datasets and red-teaming protocols appropriate to the domain.
Step 3 – Scenario Validation Against Real Business Reality
Benchmark scores are marketing material, not deployment credentials.
The decisive evaluation step is running the model against scenarios drawn directly from your operational reality: production-representative data, realistic query distributions, and edge cases surfaced by domain experts.
For regulatory reporting, that means testing against your actual filing formats, jurisdictional terminology, and exception conditions. For contract analysis, it means validating against the clause structures, governing law variations, and random language patterns in your real portfolio.
These general-purpose benchmarks don’t always reveal the failure modes. It only appear when your own data enters the system.
What we suggest is you start by maintaining a “golden dataset” — a selected library of production-like queries paired with expert-validated ground-truth answers. This dataset should be continuously expanded with live deployment data, creating a self-improving evaluation asset.
For every high-criticality use case, you must demonstrate that outputs can be traced to identifiable reasoning steps or source documents—not accepted as black-box conclusions. This creates the technical foundation of audit-trail infrastructure.
Step 4 – Post-Deployment: Continuous Monitoring
Evaluation is not a one-time gate. We think it’s quite evident.
LLMs in production are more likely to model drift — output quality degrades as real-world data distributions evolve away from training conditions. A model validated at launch can behave marginally differently six months later, without any code change. The trigger is the world changing around it.
Continuous monitoring requires three capabilities:
• Automated tracking against the golden dataset
• Alerting on response quality anomalies (factual drift, tone shift, format inconsistency, increased refusal rate)
• Structured human review pipelines that feed expert feedback back into revalidation cycles
Leading organizations treat LLM monitoring like financial controls: not a single annual audit, but continuous assurance with documented evidence available on demand for regulators and auditors.
Here’s what we suggest
Define a recurring re-evaluation cadence triggered by model updates, data distribution shifts, or regulatory changes.
qAPI can operationalize this at enterprise scale — providing automated AI validation, continuous testing pipelines embedded in CI/CD, and governance dashboards that track model performance and decision reliability over time.
What You Need To Understand: Not all LLM outputs are created equal.
One prompt can give you brilliant insight; the next (same model, slightly different wording) can hallucinate confidently wrong facts, leak sensitive data, or produce biased, unsafe, or off-brand content.
That’s where LLM evaluation becomes important for you and your teams.
Here’s how this section would look if it were written to feel more human, more valuable, and stronger for search + LLM ranking — less like product documentation, more like something people actually want to read and trust.
Evaluating LLMs Using qAPI
Most teams don’t struggle with using LLMs. They struggle with trusting them. You try using one tool get used to it, only to realize that an update later you’re out on the streets looking for a new tool to get your work done in time and the right way.
At the start, evaluation feels simple. You test a few prompts. Check the responses. Maybe compare outputs across models.
Everything looks fine. But as soon as you try to scale, things break. This is where you should start asking:
• How do we know this won’t fail in production?
• What happens when the model gives a confident but wrong answer?
• How do we test real-world impact, not just sample prompts?
• And how do we keep checking performance over time?
This is where most teams stop and look around in confusion.
Because LLM evaluation is not just about testing outputs. It’s about building a system that can continuously validate behavior.
That’s exactly the gap qAPI’s LLM evaluator is built to solve.
What qAPI Actually Does
It helps you answer one simple question: Can we trust this model in production?”
It does this by turning LLM evaluation into something that is:
• structured
• repeatable
• and scalable
Instead of writing scripts or managing multiple tools, teams can:
• test models
• validate prompts
• run benchmarks
• monitor performance
—all in one place.
Let’s walk through how this works:
- Covers What Really Matters
Before running any tests, teams need clarity. Not every LLM use case has the same risk.
A chatbot answering FAQs is very different from:
• a system suggesting financial decisions
• or generating compliance reports
qAPI helps teams define:
• what “good output” looks like
• how accurate the model needs to be
• where human review is required
This step is important because it aligns evaluation with business impact, not just technical metrics.
- Goes BeyondGeneric Benchmarks
A lot of teams rely on benchmarks like MMLU.
They’re useful — but they don’t tell the full story.
Because your model doesn’t operate in a benchmark.
It operates in your product.
qAPI allows teams to test:
• real prompts from users
• industry-specific scenarios
• edge cases that actually matter
For example:
• finance teams can test real query patterns
• support teams can simulate customer conversations
• legal teams can validate contract analysis outputs
This is where evaluation becomes practical, not theoretical.
- Scale Testing Without Scaling Effort
Manual testing works… until it doesn’t.
Once you have hundreds of prompts, multiple models, and different use cases, things get messy fast.
qAPI automates this process.
Teams can:
• run thousands of test cases
• compare outputs across models
• evaluate functionality in minutes
What used to take days now happens in a single run.
This is often the point where teams realize:
Evaluation doesn’t have to slow them down anymore.
- Get Reports That You Actually Understand
One of the biggest frustrations in LLM testing is this: You get outputs… but no clear insight.
You’re left wondering:
• Where is the model failing?
• Is this a one-off issue or a pattern?
• What should we fix first?
qAPI solves this by turning raw outputs into:
• structured reports
• functional breakdowns
• Gives a rating for the LLM tool
So Instead of guessing, teams can clearly see:
• weak areas
• inconsistent behavior
• high-risk scenarios
This makes improvement faster and more focused.
- HelpsEvaluate After Deployment
Here’s something most teams underestimate:
LLM performance changes over time.
Even if the model stays the same:
• user inputs evolve
• data changes
• edge cases increase
This leads to silent degradation. qAPI helps teams stay ahead of this by:
• Tracking performance continuously
• Detecting drift in outputs
• Re-running evaluations with updated data
This turns evaluation into a continuous safety layer, not a one-time checkpoint.
What Changes When Teams Use qAPI
When teams move to a structured evaluation system, the difference is clear.
Before the tools are scattered you need too much manual effort and even then, the releases dont feel confident.
But with qAPI you get centralized workflows, automated testing and complete clear performance visibility
Teams will benefit with faster evaluation cycles, better coverage of real-world scenarios and the best part: earlier detection of issues.
But the biggest upside to this: You can make a right decision.
A year ago, the question was: “Which model should we use?” Today, the real question is: “Which model can we trust?”
Because access to powerful models is no longer the advantage.
How you test, monitor and how quickly you catch failures will make all the difference in 2026
Final Thoughts
LLM evaluation isn’t a good start it’s a wise start.
The organizations that will lead in enterprise AI over the next decade won’t necessarily be the ones with access to the most powerful models (that edge is commoditizing fast). They will be the ones that can:
– Deploy generative AI responsibly
– Sustain performance reliably over time
– Demonstrate integrity and compliance credibly to regulators, auditors, and boards
Structured, continuous LLM evaluation is now a best bet for high-stakes use cases. It is the minimum viable control framework needed to manage real financial, legal, and reputational risk.
The four steps outlined here—defining decision criticality, stress-testing hallucinations and bias, validating against real business scenarios, and implementing continuous monitoring—are not aspirational best practices. They are the operational baseline any prudent risk leader or CIO should demand today.
The question isn’t whether your organization can afford to build this evaluation discipline.
It’s whether you can afford not to—while competitors quietly reduce their exposure, accelerate safe adoption, and gain regulatory and market trust you’re still trying to earn.
In regulated and consequential domains, trust is no longer granted.
It is proven—every day, in production, under scrutiny.
qAPI exists to make that proof systematic, auditable, and scalable—so you can move fast without moving recklessly.
The future belongs to the organizations that treat evaluation as seriously as they treat innovation.
Which side will yours be on?
If you’re ready to move from “it seems fine” to “we know it’s reliable”, start with qAPI.
What’s your biggest pain point with LLM evaluation today?
Manual reviews? Hallucinations slipping through? Regression surprises?
Drop it in the comments — we read every one.
References
1.Agarwal, S. (2025). How to Select the Right Large Language Model. Gartner Research Note G00794364.

