We shipped four major upgrades this month that directly solve the hardest problems our power users keep running into. Here’s what’s new and why it matters to you right now.
1. Secure Pipelines: Token-Based Authentication Is Live!
Integrating API testing platforms into CI/CD pipelines or external developer tools gave users both security and reliability issues. Using standard user login sessions for automated workflows is fragile—sessions expire frequently, leading to unexpected build failures. On top of that, exposing real user credentials to third-party tools creates serious security risks.
What we built
Full User Token + API Key authentication across every qAPI endpoint — battle-tested in staging and now rolled out to production.
• Zero Pipeline Downtime: Use dedicated API keys for machine-to-machine communication. No more broken builds due to session timeouts.
• Enterprise Security: Safely connect qAPI to your favorite tools and scripts without ever exposing user passwords.
• Effortless Automation: Generate simple, secure tokens to kickstart headless testing workflows instantly
2. AI-Powered Testing: Semantic LLM Evaluations
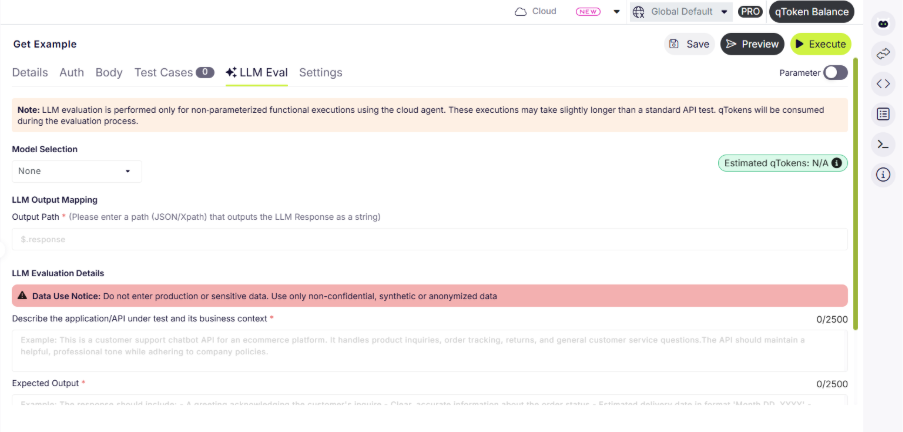
Testing GenAI endpoints with exact-match assertions is officially dead.
Most API testing hinges on exact-match rules—specific strings, regex patterns, fixed JSON paths. But in a world flooded with GenAI and NLP outputs, responses are increasingly variable. A perfectly valid answer might be worded completely differently each time. Strict assertion logic flags these as failures, creating a pile of false negatives and dragging QA teams into tedious manual review.
Dynamic responses change phrasing every call, yet mean the same thing → traditional tests scream false failures → you waste hours manually reviewing “broken” tests.
What we built
We built a brand-new Semantic Evaluation test type powered by an LLM-as-a-judge model, right inside your API test cases. Instead of checking character-by-character, it assesses whether the meaning of a response aligns with what you expect.
You only have to share the context, your expected outcome, and optional safety rails. qAPI pulls the live response output (from JSON/XML paths or a custom override) and feeds it to an LLM that scores it against your criteria.
What you get
• Validate What Was Previously Impossible: Dynamic text, conversational AI outputs, and generated content can all be tested reliably—no more brittle keyword guards.
• Rich, Contextual Feedback: Your execution panels now include a dedicated Semantic Evaluator tab. It delivers a relevance score and a detailed judge commentary that breaks down what worked and what didn’t in the response.
• Configurable Pass/Fail Logic: Define your own thresholds. The AI judge will classify each result as a Pass, Fail, or flag it for human Review based on the boundaries you set.
• Plug Right Into Existing Workflows: Design sophisticated AI-backed assertions with very little setup and attach them directly to your current test suites.
You can finally test chatbots, LLM wrappers, search APIs, and content generation endpoints without constant test maintenance.
3.Full LLM Model Visibility in Execution Reports
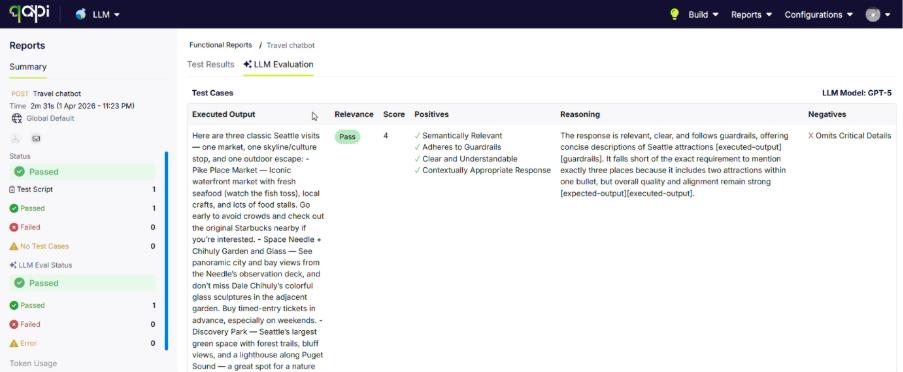
Semantic Evaluations was supposed to give you the ability to let AI assess dynamic responses—but when you’re juggling multiple LLM providers or model versions across different test suites, your reports don’t tell you which model evaluated which test. That blind spot makes it hard to audit decisions, compare model performance across runs, or figure out why a particular evaluation seems off.
What We Did About It:
We upgraded the reporting engine to capture and surface the exact LLM model used for every semantic evaluation. We also cleaned up the result terminology so that AI-generated feedback, scores, and statuses are easier to interpret at a glance.
Why This Matters:
• End-to-End Traceability: Every evaluation now shows precisely which model did the judging—no more guesswork about what produced a given score.
• Sharper Root-Cause Analysis: Pinpoint whether an unreliable semantic test stems from the prompt, the actual API output, or the particular LLM version acting as the judge.
• Cleaner, More Digestible Reports: Streamlined wording across summaries, scoring, and pass/fail indicators removes confusion and speeds up your review process.
4. Faster Previews, On-Time Schedules, and Flawless Wallet Sync
As testing volumes climb into the millions, the backend systems responsible for credit management, scheduling, and live previews start showing their age. You may have noticed occasional lag when rendering previews for large payloads, slight timing drifts on automated schedules during peak hours, or sync headaches when managing qToken wallets across a big team.
What We Did About It
We rebuilt the backend logic for three foundational qAPI components from the ground up: qToken wallet management, the execution scheduler, and the API preview engine. Older processing paths have been replaced with a modern, highly optimized architecture engineered for enterprise-scale throughput and reliability.
What You’ll Experience:
• Fast Previews: Complex payloads, custom headers, and AI evaluation previews now render almost instantly—no more staring at loading spinners.
• Clockwork Scheduling: Automated test suites fire at precisely the scheduled moment. Backend queuing delays are eliminated, even during your busiest testing windows.
• Real-Time Wallet Accuracy: qToken balances and allocations sync instantly and securely across every user in your organization. Team-level resource management just became completely hands-off.
Our goal is to give you a platform that evolves alongside your needs—removing friction from critical workflows so your team can ship higher-quality software with greater velocity and confidence.
The best way to understand the impact? See it in action.
Log on to qapi.qyrus.com
All features above are live in production today.
The difference is night and day when you see it on your own APIs.

