Every AI product team is talking about leveraging AI. But why does your AI sound brilliant in demos… but struggle with real user questions? Why can’t it answer about your latest pricing, internal docs, or customer cases? And why does it sometimes confidently give answers that are just… wrong?
Here’s why it happens
You plug a good LLM into your product—GPT-4o, Claude, Gemini, Llama 3. The results are impressive. It writes fluently. It sounds intelligent. It feels like magic.
Then if you try to use it in the real world, problems arise. Because you need it to answer questions about your internal documentation. Your product database. Your compliance policies. Last month’s pricing update. The customer case filed three days ago.
And it can’t.
Not because the model is dumb. Because the model doesn’t know.
Its knowledge is frozen in time, sealed at whatever date it stopped training. Everything that happened after that date — every document your company wrote, every update your team published, every piece of context that makes your application genuinely useful — is invisible to it.
This is the problem RAG was built to solve.
Retrieval-Augmented Generation is one of the most consequential architectural patterns in modern AI development. It’s the reason enterprise AI assistants can answer questions about real documents. It’s why AI-powered customer support can reference live product data. It’s how legal AI tools cite actual case law instead of inventing it.
This guide covers everything product teams need to understand about RAG — what it is, how it works, the seven types you’ll encounter in production, the four complexity levels that determine what architecture you actually need, and the critical decision between RAG and LLM fine-tuning that every team building with AI will eventually face.
What Is RAG? The Core Concept Explained Simply
RAG stands for Retrieval-Augmented Generation. Basically, it’s an architectural pattern that gives an LLM access to external knowledge before it generates a response.
Here’s the simplest way to understand it.
A standard LLM is like a doctor who graduated medical school in 2022 and hasn’t read a single paper, attended a conference, or updated their knowledge since. They’re highly intelligent. Highly capable.
But everything they know is from before they graduated. Ask them about a treatment protocol published last month — they can’t help you. They might fabricate an answer that sounds convincing, because that’s what LLMs do when they don’t know something. But it will be wrong.
RAG is like giving that same doctor access to a medical library before they answer your question. They still bring the intelligence, the reasoning, the language ability. But now, before they respond, they look up the relevant papers. They pull the current guidelines. They check the most recent research. Then they answer.
The output isn’t just smarter. It’s grounded in something real and verifiable.
Technically, as AWS defines it: RAG is the process of optimizing the output of an LLM so it references an authoritative knowledge base outside of its training data sources before generating a response. The key phrase is “outside of its training data” — this is the information that didn’t exist when the model was trained, or that belongs specifically to your organization and will never be in any public training set.
The Two Components of Every RAG System
Every RAG implementation — regardless of complexity — has two core components working in sequence:
The Retriever: This component takes the user’s query, searches your external knowledge base (usually a vector database), and pulls back the most relevant chunks of information. It’s essentially a smart search engine that understands semantic meaning, not just keyword matching.
The Generator: This is your LLM. It takes the user’s original query plus the retrieved context and generates a response that synthesizes both. The model isn’t just reciting what it found — it’s reasoning over the retrieved documents to produce a coherent, useful answer.
What comes out is more accurate, more specific, more up-to-date, and — critically — it can point to sources.
Why Is Everyone Talking About RAG Right Now?
RAG isn’t new. The foundational research from Meta AI, University College London, and New York University dates to 2020. But the reason it’s a primary topic for every serious AI team in 2025–2026 is the intersection of three forces that are happening simultaneously.
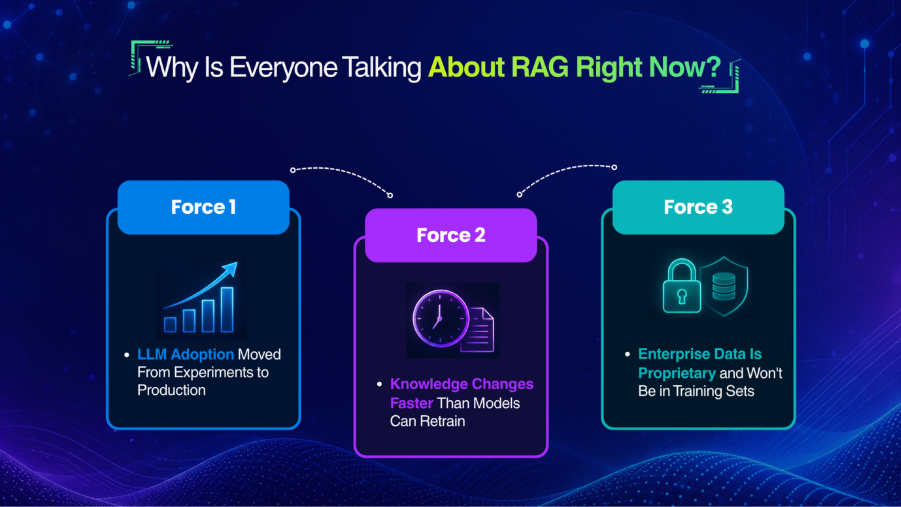
Force 1: LLM Adoption Moved From Experiments to Production
In 2023, most teams were building demos and exploring what was possible. In 2025 and 2026, those teams are shipping production applications — customer-facing products, internal tools, workflow automations — that need to perform reliably. And production performance means you can’t accept hallucinations, stale data, or inability to access proprietary knowledge. RAG is the architectural solution to all three of those problems.
Force 2: Knowledge Changes Faster Than Models Can Retrain
An LLM training run is expensive, slow, and permanent. Once a model is trained, its internal knowledge is frozen. But the real world doesn’t freeze. Regulations change. Products update. Markets shift. New research publishes daily. The gap between what an LLM was trained on and what’s actually true today grows continuously.
RAG bridges that gap without requiring retraining. Your knowledge base updates in real time. The model stays the same. The outputs stay current.
Force 3: Enterprise Data Is Proprietary and Won’t Be in Training Sets
The most valuable knowledge for most organizations — their internal documentation, customer history, contracts, processes, and institutional memory — will never appear in a public LLM training set. It’s private. It’s sensitive. It’s specific to them.
RAG is the mechanism that lets organizations keep their data private and still make it usable by AI. You don’t hand your data to OpenAI to retrain the model. You store it in your own vector database, retrieve from it at query time, and never expose it in bulk to anyone.
This alignment with enterprise priorities — accuracy, explainability, data privacy, cost efficiency, and compliance — is exactly why RAG has gone from a research pattern to a production architecture standard in under three years.
How RAG Works: The Three-Step Pipeline
Understanding RAG will immediately remove a lot of confusion for you. The process follows three stages, regardless of which variant you’re building.
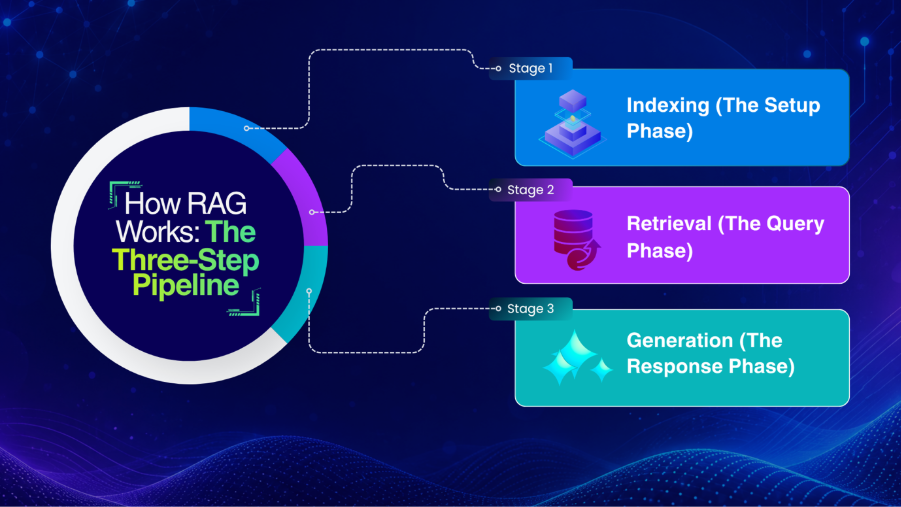
Stage 1: Indexing (The Setup Phase)
Before any query happens, you prepare your knowledge base. This means:
- Document ingestion: You feed your external knowledge — PDFs, web pages, database records, API outputs, help documentation, whatever is relevant — into the system.
- Chunking: Documents are broken into smaller pieces. A 40-page user manual becomes 200 bite-sized chunks that can each be retrieved independently. The chunk size matters — too small and you lose context, too large and retrieval becomes imprecise.
- Embedding: Each chunk is converted into a numerical vector — a long list of numbers that represents the semantic meaning of that text. Two sentences that mean similar things will have similar vectors, even if they use different words.
- Vector storage: These embeddings are stored in a vector database — tools like Pinecone, Weaviate, Qdrant, Chroma, or Milvus are built for this purpose.
Stage 2: Retrieval (The Query Phase)
When a user asks a question:
- The query is converted into an embedding using the same model that was used for the documents.
- The system performs a similarity search across the vector database — mathematically finding which stored chunks are most semantically similar to the query.
- The top-k most relevant chunks are retrieved. These might be 3 chunks, 10 chunks, 20 chunks — this is a configurable parameter that trades precision against context window size.
Stage 3: Generation (The Response Phas e)
- The retrieved chunks are injected into the LLM’s context window alongside the original query.
- The LLM generates a response that synthesizes the retrieved information with its training knowledge.
- The output is grounded in your actual documents — and can cite specific sources.
This is the fundamental pipeline. Everything from Naive RAG to Agentic RAG is a variation on this three-stage flow.
The 7 Types of RAG (And When to Use Each)
The RAG landscape has matured significantly. What started as one approach has differentiated into seven distinct types, each suited to different use cases and problem profiles. Here’s what each one actually is and when it’s the right choice.
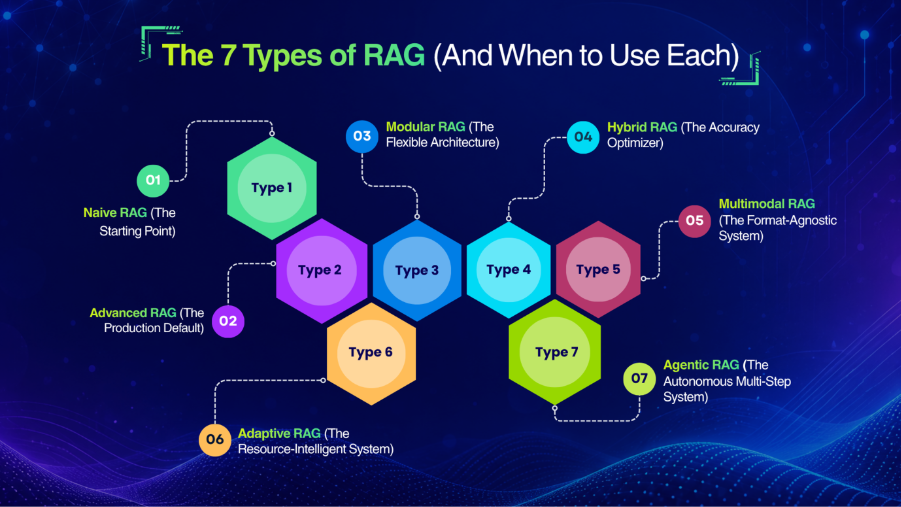
Type 1: Naive RAG (The Starting Point)
Naive RAG is the original implementation of the pattern. It’s straightforward: take a query, convert it to an embedding, retrieve the closest matches from a vector database, stuff those matches into the prompt, generate a response. No filtering, no reranking, no optimization.
How it works: Query → embedding → vector similarity search → top-k results → prompt → LLM → response. There’s no step where you evaluate whether the retrieved documents are actually relevant or whether the response is accurate.
Where it works well: Simple chatbots with a predictable, bounded scope. Internal FAQ systems where questions are predictable and the knowledge base is small and clean. Rapid prototypes where you need to validate whether a RAG approach is viable before investing in optimization.
Where it breaks: When queries are ambiguous or multi-hop (requiring information from multiple documents). When the knowledge base is noisy. When the question and the answer use different vocabulary. Naive RAG struggles with low precision — it retrieves misaligned chunks — and low recall — it fails to retrieve all the relevant chunks that exist.
The honest assessment: Naive RAG is a good proof-of-concept. It’s not a production architecture for complex applications.
Type 2: Advanced RAG (The Production Default)
Advanced RAG is Naive RAG with optimization layers added before and after retrieval. It’s the minimum viable architecture for most production applications.
Pre-retrieval optimizations include:
- Query rewriting: The user’s query is rewritten or expanded before retrieval to improve the semantic match with stored documents. A vague user question becomes a more precise retrieval query.
- HyDE (Hypothetical Document Embeddings): The model generates a hypothetical ideal answer, embeds that, and uses it to retrieve documents. This improves retrieval when the question and the answer space use different language.
- Better chunking strategies: Semantic chunking (splitting on topic boundaries rather than fixed token counts) produces better retrieval than naive fixed-size chunking.
Post-retrieval optimizations include:
- Reranking: A second model (a cross-encoder) re-scores the retrieved chunks for relevance. The initial retrieval casts a wide net; the reranker picks the best fish.
- Context compression: Irrelevant portions of retrieved chunks are filtered out before being passed to the LLM, reducing noise and preserving context window space for the most useful content.
Where it works well: Most standard production applications — customer support assistants, internal knowledge bases, documentation search, product Q&A. The combination of better retrieval and better context handling makes this the right default.
The benchmark guidance: Advanced RAG is the sweet spot of cost versus quality for the majority of use cases. If Naive RAG accuracy isn’t meeting your bar, add hybrid retrieval and a re ranker before considering anything more complex.
Type 3: Modular RAG (The Flexible Architecture)
Modular RAG is the architectural evolution that treats RAG not as a fixed pipeline but as a set of composable modules that can be assembled, replaced, and extended.
How it works: Instead of a fixed retrieve-augment-generate sequence, Modular RAG decomposes the system into specialized components:
- Search module: Handles retrieval from multiple sources simultaneously — vector databases, search engines, APIs, SQL databases.
- Memory module: Stores past interactions to maintain context across multi-turn conversations.
- Routing module: Decides which retrieval source and strategy is appropriate for a given query type.
- Task adapter: Adjusts retrieval behavior for specific task types — summarization, Q&A, comparison, extraction.
- Fusion module: Combines results from multiple retrieval strategies.
Where it works well: Complex enterprise applications where different query types need different retrieval strategies. Multi-domain knowledge bases where a single retrieval approach can’t cover all cases. Applications that need to iterate and improve components independently without rebuilding the entire pipeline.
The key insight: Both Naive RAG and Advanced RAG are actually special cases of Modular RAG — they’re just Modular RAG with fixed modules. Modular RAG is what you build when your fixed pipeline is no longer flexible enough.
Type 4: Hybrid RAG (The Accuracy Optimizer)
Hybrid RAG combines multiple retrieval methods — typically dense vector search and sparse keyword search — to capture what each method alone would miss.
The problem it solves: Dense vector search is excellent at finding semantically similar content even when phrasing differs. But it can miss exact keyword matches that a user or document might require. Sparse search (BM25, traditional TF-IDF) is excellent for exact term matching but misses semantic similarity. Hybrid RAG uses both, then fuses the results.
How it works: A query is run through both a vector similarity search and a keyword-based search simultaneously. The results from both pipelines are then combined using a fusion strategy — Reciprocal Rank Fusion (RRF) is common — that blends the two result sets into a single ranked list.
Where it works well: Domain-specific applications where precise terminology matters — legal documents with specific clause numbers, medical literature with exact drug names, technical documentation with specific error codes. Any scenario where you need both semantic understanding and exact-match precision.
The production note: Enterprise RAG implementations are increasingly defaulting to hybrid retrieval because it consistently outperforms single-method pipelines on accuracy, especially in noisy enterprise datasets.
Type 5: Multimodal RAG (The Format-Agnostic System)
Multimodal RAG extends retrieval beyond text to handle images, audio, video, tables, charts, diagrams, and structured data — any information format that real-world knowledge actually lives in.
How it works: Documents are processed not just as text but as their native formats. Charts are analyzed for their underlying data. Images are embedded using vision models. PDFs with tables have those tables extracted and indexed separately from the surrounding prose. Audio is transcribed and processed. The retrieval system then queries across all these modalities based on a text prompt.
Where it works well: Industries where knowledge is inherently multimodal — engineering and manufacturing (equipment manuals with diagrams), healthcare (clinical documentation with imaging), financial analysis (reports with charts and tables), product management (design documents, user research videos). Anywhere the answer to a question might live in a graph rather than a paragraph.
The current reality: As of mid-2025, Multimodal RAG has not fully lived up to its early momentum because the supporting infrastructure remains immature. Late interaction models are still dominating the space, meaning embedding models produce multi-vector representations (a single image may require over 1,000 vectors) that create significant storage and retrieval overhead. The capability is real; the production cost is still high.
Type 6: Adaptive RAG (The Resource-Intelligent System)
Adaptive RAG adds a decision layer that evaluates whether retrieval is even necessary for a given query, and if so, how much.
How it works: Before retrieval, a classifier or small model evaluates the query. If the answer is something the base LLM already knows well (a general factual question, a simple calculation, a generic task), retrieval is skipped entirely. If the query requires specific external knowledge, retrieval is triggered — and the complexity of retrieval scales with how specific the need is.
Where it works well: High-volume applications where retrieval costs (latency and compute) matter significantly. Chatbots that handle a mix of general questions and domain-specific questions. Scenarios where adding retrieval latency to every query would degrade user experience.
The trade-off: You’re optimizing for cost and speed by being selective. The risk is that the classifier misfires — decides to skip retrieval when retrieval was needed — and the LLM falls back to hallucinating from training data. Adaptive RAG requires a well-calibrated routing model.
Type 7: Agentic RAG (The Autonomous Multi-Step System)
Agentic RAG replaces the linear pipeline with an autonomous agent that plans, retrieves, evaluates, and re-retrieves in a loop until the query is fully addressed.
How it works: The user’s query is handed to an agent (itself powered by an LLM) that breaks the query into sub-questions, plans a retrieval strategy, retrieves documents, evaluates whether what was retrieved is sufficient to answer the sub-questions, and iterates — retrieving again, from different sources, with different queries — until the agent is confident it has enough context to generate a complete answer.
For a query like “Compare our Q3 performance against industry benchmarks and identify where we underperformed,” an Agentic RAG system might retrieve Q3 internal financial data, retrieve industry benchmark data from an external source, retrieve prior quarter data for context, and synthesize all three — not because it was told to, but because the agent reasoned that all three were necessary.
Where it works well: Complex, multi-hop queries that require combining facts across multiple documents or sources. Research applications where the system needs to reason about what it doesn’t yet know and go find it. Autonomous workflows where the answer requires a sequence of information-gathering steps.
The critical warning: Agents amplify errors. A 5% error rate in each step of a ten-step reasoning chain produces a significantly degraded output even if no individual step fails catastrophically. Agentic RAG is powerful and demands a trajectory evaluation strategy — evaluating the sequence of decisions and retrievals, not just the final output.
The 4 Levels of RAG Complexity
Beyond the seven types, there’s a second framework that’s equally important for product teams: the four levels of RAG complexity. Where the types describe the architecture, the levels describe the cognitive task complexity of the queries your system needs to handle.
This framework comes from Microsoft Research and classifies RAG applications based on the type of external data and the cognitive processing required.
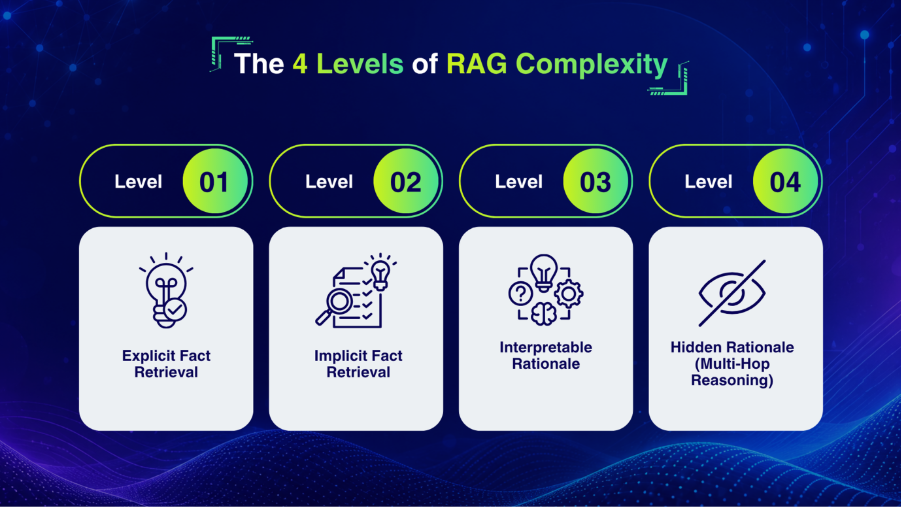
Level 1: Explicit Fact Retrieval
What it is: Direct factual queries where the answer is explicitly stated somewhere in the knowledge base. The model retrieves the statement and surfaces it.
Example queries: “What is the refund policy?” “What does the error code 403 mean in our system?” “What’s the maximum file size the API accepts?”
What the retrieval looks like: Semantic similarity search finds the document containing the answer. The LLM reads it and reports it.
Architecture required: Naive or Advanced RAG handles this well. The core requirement is high-quality chunking and embedding so the right document is actually retrieved.
Level 2: Implicit Fact Retrieval
What it is: Queries where the answer isn’t stated explicitly but can be derived from what is. The model must synthesize across multiple retrieved documents to produce an answer that isn’t directly written anywhere.
Example queries: “Based on our current SLA commitments and last quarter’s incident data, how many times did we fall short?” “What do our top three competitors have in common that we don’t offer?”
What the retrieval looks like: Multiple documents are retrieved and the model must combine information from them. The answer doesn’t exist as a single statement — it’s constructed from the combination.
Architecture required: Advanced RAG with reranking, and potentially Modular or Hybrid RAG to ensure all relevant documents are surfaced. The model needs enough retrieved context to make the synthesis.
Level 3: Interpretable Rationale
What it is: Queries that require the model to not just retrieve facts and synthesize them, but to apply domain-specific rules, constraints, or reasoning frameworks to those facts.
Example queries: “Given our data retention policy and GDPR compliance requirements, should we honor this deletion request?” “Based on our pricing rules and this customer’s contract tier, what discount are they eligible for?”
What the retrieval looks like: The model must retrieve both the factual data (the customer contract, the deletion request) and the relevant rules (the compliance policy, the pricing framework) and then reason about how the rules apply to the facts.
Architecture required: Advanced or Modular RAG, often with structured data retrieval alongside unstructured document retrieval. This level is where many teams first discover that Naive RAG is insufficient.
Level 4: Hidden Rationale (Multi-Hop Reasoning)
What it is: The most complex level. Queries that require multiple retrieval passes — where the answer to the first retrieval step determines what to retrieve next, and so on — to piece together an answer that requires multi-step logical inference.
Example queries: “When was the last time Jerry Rice and Steve Young played on the same NFL team?” (requires retrieving both players’ careers, then finding the intersection) “Which of our customers who adopted Feature X before July 2024 have NOT renewed since the pricing change?”
What the retrieval looks like: The model retrieves initial data, reasons about what additional data it needs based on the first results, retrieves again, reasons again. This is inherently iterative, not linear.
Architecture required: Agentic RAG with chain-of-thought prompting guiding the retrieval steps. Graph-based RAG is also well-suited here, as relationship traversal naturally handles multi-hop reasoning. Standard one-shot retrieval will fail at this level.
RAG vs LLM: Understanding the Real Difference
This question comes up constantly and the confusion is understandable because people use “LLM” to mean two different things.
When someone asks “should I use RAG or an LLM?”, they usually mean: should I just call the LLM API directly, or should I build a RAG layer in front of it?
The answer requires understanding what each approach actually does with knowledge.
What an LLM Is
A Large Language Model is a neural network trained on massive amounts of text. During training, patterns from that text are compressed into the model’s billions of parameters — its weights. The model learns language, reasoning patterns, facts, relationships, and concepts from everything it was trained on.
When you call an LLM directly, you’re accessing that compressed knowledge. The model generates responses from what it learned during training, combined with whatever you put in the current context window.
The fundamental constraint: The model’s internal knowledge is frozen at its training cutoff. It doesn’t know what happened yesterday. It doesn’t know what’s in your internal documents. It doesn’t know about the pricing change you made last week. And — critically — when it encounters a question it doesn’t have a good answer for, it doesn’t say “I don’t know.” It generates a plausible-sounding answer based on the patterns it learned. That’s a hallucination.
What RAG Does Differently
RAG doesn’t replace the LLM. It adds a retrieval layer that runs before the LLM generates a response.
The difference is in where the knowledge comes from. An LLM-only system generates from parametric memory — the patterns baked into its weights. A RAG system also generates from retrieved context — documents pull ed from external sources at the moment of the query.
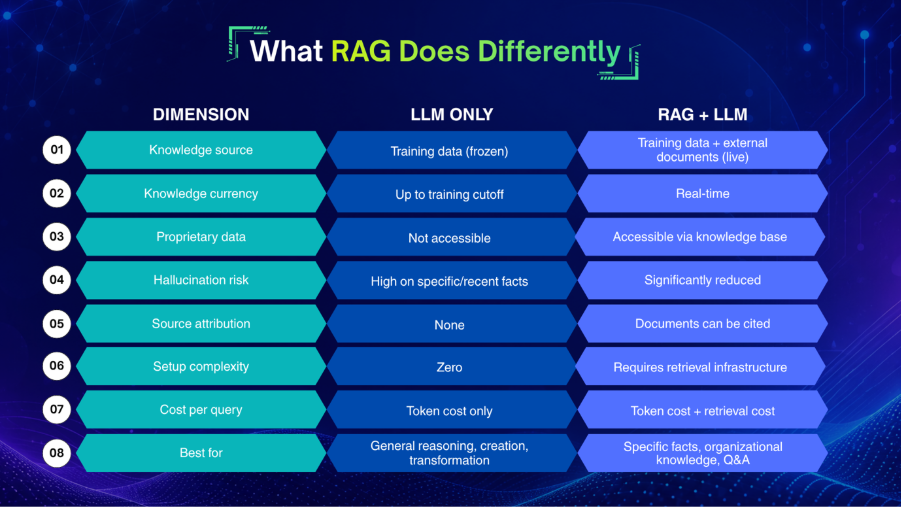
| Dimension | LLM Only | RAG + LLM |
|---|---|---|
| Knowledge source | Training data (frozen) | Training data + external documents (live) |
| Knowledge currency | Up to training cutoff | Real-time |
| Proprietary data | Not accessible | Accessible via knowledge base |
| Hallucination risk | High on specific/recent facts | Significantly reduced |
| Source attribution | None | Documents can be cited |
| Setup complexity | Zero | Requires retrieval infrastructure |
| Cost per query | Token cost only | Token cost + retrieval cost |
| Best for | General reasoning, creation, transformation | Specific facts, organizational knowledge, Q&A |
The Most Important Reframe
RAG and LLM aren’t competing options. RAG uses an LLM — it just gives the LLM better context to work with. The question isn’t “RAG or LLM?” It’s “LLM only, or LLM with retrieval?”
As one production guide puts it: most mature AI teams aren’t choosing one over the other. They’re running LLMs for generation and RAG to keep those outputs grounded in real, current, specific knowledge.
RAG vs Fine-Tuning: The Decision That Shapes Your Roadmap
Fine-tuning is the other major technique for making an LLM more useful for a specific domain or task. Understanding when to use RAG versus fine-tuning — and when to use both — is one of the most consequential architectural decisions an AI product team makes.
What Fine-Tuning Actually Does
Fine-tuning updates the weights of a pre-trained LLM by training it on additional domain-specific data. The model’s internal parameters change. It becomes better at the specific patterns, vocabulary, tone, and task format represented in your fine-tuning data.
Think of fine-tuning as changing how the model behaves. RAG changes what the model can see.
The Core Decision Rule
Put volatile knowledge in retrieval. Put stable behavior in fine-tuning.
This rule covers most cases:
- If your knowledge changes frequently (product data, pricing, regulations, news), use RAG. Updating a vector database is fast and cheap. Retraining a model is slow and expensive.
- If you need to change how the model responds — its output format, its tone, its reasoning style for a specific task type, its domain-specific language — use fine-tuning.
- If you need both accurate, current knowledge AND specific behavioral adaptation, use both together.
The Practical Comparison
RAG is better when:
- Your knowledge updates regularly (weekly, daily, or faster)
- You need source attribution and verifiability
- Data privacy requires keeping content out of model weights
- You want to change what the model knows without retraining
- You’re cost-constrained and can’t afford fine-tuning compute
- You’re in an early stage and need to iterate quickly
Fine-tuning is better when:
- You need a consistent output format or style the base model doesn’t produce naturally
- Your domain has specific jargon, vocabulary, or reasoning patterns
- Response latency is critical (fine-tuned models can be faster — no retrieval step)
- You have enough labelled data to produce meaningful adaptation
- Your knowledge is stable and won’t change significantly
An important architecture note from 2025 and 2026 production experience: If your total knowledge base fits comfortably within an LLM’s context window (for many use cases, this means under roughly 200,000 tokens), full-context prompting with prompt caching may be faster and cheaper than building retrieval infrastructure at all. This is a significant architectural simplifier for bounded internal tools and documentation assistants. RAG is the right choice when your knowledge base is too large to fit in context, or when you need selective, precise retrieval from a large corpus.
What Product Teams Need to Know About RAG
Here’s the layer of knowledge that most technical guides skip — the practical things that determine whether your RAG implementation ships and works, not just whether it’s architecturally correct.
- Retrieval Quality Is the Whole Game

The quality of your RAG output is almost entirely determined by the quality of what you retrieve. If the relevant document is in the knowledge base but retrieval doesn’t surface it, the LLM can’t use it. If noisy, irrelevant chunks are retrieved, they degrade the response. The most common production failure mode in RAG is not poor generation — it’s poor retrieval.
This means chunking strategy, embedding model choice, reranking, and knowledge base curation are not infrastructure details. They’re product quality decisions.
- Garbage In, Garbage Out — But at Retrieval Speed
A RAG system is only as good as the knowledge base it retrieves from. Outdated documentation, inconsistent terminology, poorly structured content, and duplicate entries all degrade retrieval precision. Before building your RAG pipeline, audit your knowledge base. Treat it as a first-class data product, not a file dump.
- Evaluation Is Not Optional
How do you know your RAG system is working? Not from the demo. Not from your own test queries. From systematic evaluation against a representative benchmark dataset of real user questions, with defined quality metrics.
The minimum metrics to track:
- Answer relevance: Is the generated answer actually addressing the question?
- Faithfulness: Is the answer grounded in the retrieved documents, or is the model drifting to hallucination?
- Context recall: Are the right documents being retrieved? Are relevant documents being missed?
- Context precision: Of what’s being retrieved, how much of it is actually relevant?
Tools like RAGAS provide automated frameworks for evaluating these dimensions at scale. This is non-negotiable for production systems.
- RAG Has a Latency Cost — and You Need to BudgetForIt
Adding a retrieval step adds latency. Depending on your vector database, embedding model, reranking step, and network conditions, a RAG system adds 100ms–800ms compared to a direct LLM call. For some applications this is irrelevant. For a real-time customer support interface, it matters enormously.
Design for this from the start: asynchronous loading indicators, streaming responses that begin while retrieval completes, and architectural choices that parallelize retrieval where possible.
- Chunking Is a Product Decision,Nota Technical Default
Most developers set chunk size once, use a default value, and forget about it. But chunk size determines what unit of information gets retrieved, and different applications have very different optimal chunk sizes.
- Short chunks (128–256 tokens) give high precision — you retrieve only what’s relevant — but lose surrounding context that helps the model understand the retrieved fragment.
- Long chunks (512–1024 tokens) preserve context but introduce noise and eat context window space.
- Hierarchical chunking (small chunks for retrieval, larger parent chunks for context) is the emerging best practice for most production systems.
The right chunk size depends on your content type, your query distribution, and your context window budget. Test it explicitly rather than accepting defaults.
Security and Access Control Are Your Responsibility
RAG systems connect your LLM to your internal data. If that data contains sensitive information — which it almost always does — you are responsible for ensuring the right users can only retrieve documents they’re authorized to see.
This means implementing access control at the retrieval layer, not just the application layer. A retrieved document that a user wasn’t authorized to see shouldn’t appear in the LLM’s context, regardless of how the LLM handles it from there.
RAG in Practice: Industry Use Cases That Actually Work
Legal and Compliance
Legal AI assistants use RAG to retrieve actual case law, regulatory text, contract clauses, and compliance requirem ents before answering legal questions. This is a category where hallucination has serious consequences — citing a case that doesn’t exist, or misrepresenting a regulatory requirement, creates real liability. RAG grounds every response in retrievable, citable sources.
Real pattern: A question about contract termination rights triggers retrieval of the relevant contract clauses, the applicable jurisdiction’s statutes, and recent case law — then generates an answer that cites all three.
Healthcare
Medical AI systems cannot afford to generate responses from 2022 training data when clinical guidelines were updated in 2024. RAG connects medical AI to live clinical guidelines, current drug interaction databases, and real-time diagnostic protocols. A 2025 study in npj Health Systems found that RAG-powered AI transforms healthcare by integrating real-time diagnostic data and the latest clinical research, ensuring medical decisions are based on current information.
Real pattern: A question about a drug interaction retrieves the current interaction database entry, the relevant clinical guideline, and any recent FDA safety updates — then synthesizes a response that reflects the latest available guidance.
Financial Services
Financial markets change by the second. Static model knowledge is useless for portfolio analysis, earnings interpretation, or regulatory compliance in a domain that operates in real time. Banks and investment firms use RAG to enable AI analysts that retrieve live market reports, earnings transcripts, and macroeconomic data before generating responses.
Real pattern: An analyst asks about a company’s debt position. The RAG system retrieves the most recent earnings call transcript, the Q2 10-Q filing, and current credit market data — then generates a synthesis with source citations that can be independently verified.
Customer Support
Customer support is one of the most common RAG deployments because the product knowledge base changes continuously — pricing, features, policies, known issues. A RAG-powered support system stays current automatically as the knowledge base updates, without requiring model retraining.
Real pattern: A customer asks why their API key isn’t working. The system retrieves the current authentication documentation, the recent changelog entry about a breaking change, and the troubleshooting guide — and generates a specific, accurate response rather than generic advice.
Internal Knowledge Management
Enterprise organizations contain enormous amounts of institutional knowledge locked in documents, wikis, emails, and databases that employees can’t efficiently search. RAG-powered internal assistants let employees ask natural language questions and get answers grounded in actual internal documentation — with citations they can follow to the source.
How to Evaluate If Your RAG System Is Working
Building a RAG system is the first step. Knowing whether it’s actually working is the step most teams skip.
The Four Core Evaluation Metrics
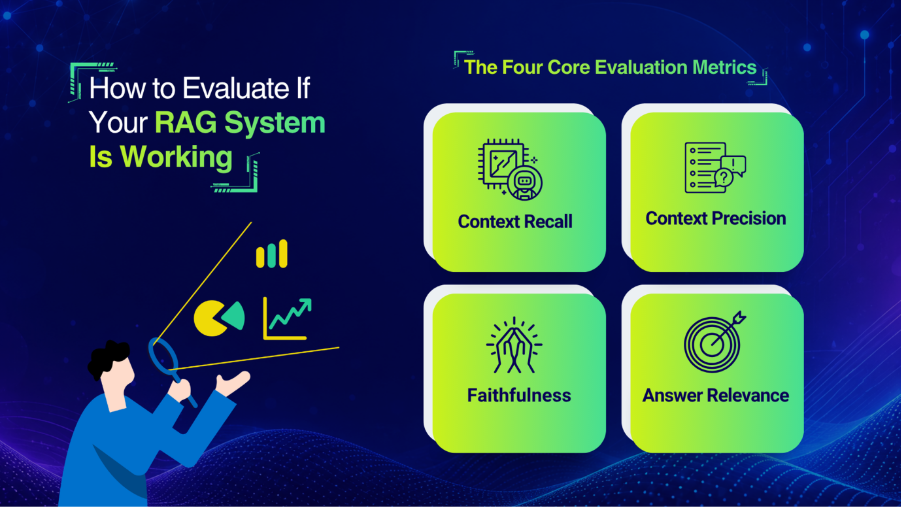
Context Recall asks: Of all the relevant documents that exist in the knowledge base, what percentage are actually being retrieved? This measures whether your retrieval is finding what it should find. Low recall means relevant information exists but isn’t surfacing.
Context Precision asks: Of everything being retrieved, how much of it is actually relevant? High precision means your retrieval is focused and not surfacing noise. Low precision means the LLM is being given too much irrelevant information, which degrades generation quality.
Faithfulness asks: Is the generated answer actually grounded in the retrieved documents? A high faithfulness score means the model is using what it retrieved. A low faithfulness score means the model is drifting — hallucinating content that wasn’t in the retrieved context.
Answer Relevance asks: Does the final response actually address what the user asked? This is the end-to-end quality metric that matters to users.
The Evaluation Rule for RAG
A RAG system can fail at retrieval (right documents not found), at augmentation (retrieved documents not being used effectively), or at generation (the LLM producing a poor answer from good context). Evaluation must cover all three stages independently, because a failure at any stage produces a bad output even if the other two stages are working correctly.
Building a RAG Evaluation Dataset
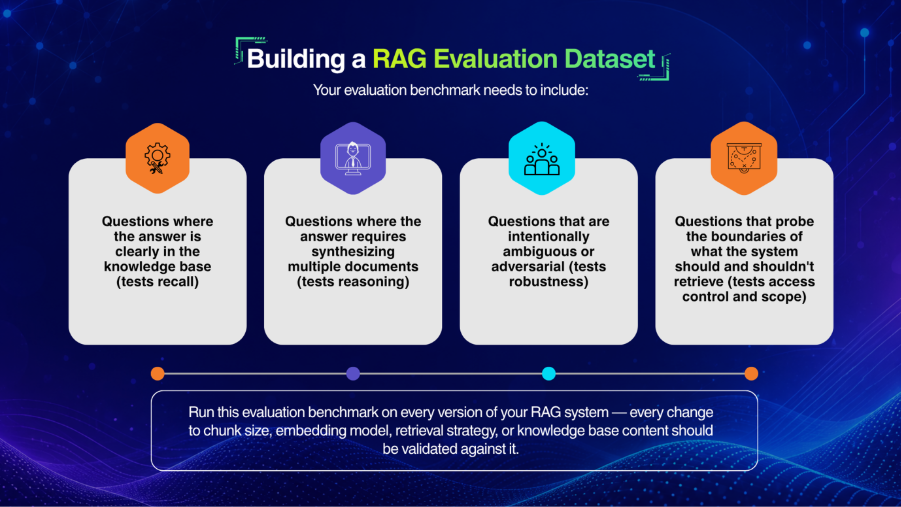
Your evaluation benchmark needs to include:
- Questions where the answer is clearly in the knowledge base (tests recall)
- Questions where the answer requires synthesizing multiple documents (tests reasoning)
- Questions that are intentionally ambiguous or adversarial (tests robustness)
- Questions that probe the boundaries of what the system should and shouldn’t retrieve (tests access control and scope)
Run this evaluation benchmark on every version of your RAG system — every change to chunk size, embedding model, retrieval strategy, or knowledge base content should be validated against it.
Conclusion: RAG Is an Architecture Decision,Not a Feature
The most important framing shift for product teams thinking about RAG: it’s not a feature you add to an LLM application. It’s an architectural decision about where your AI product’s intelligence lives.
An LLM-only system puts all its intelligence inside model weights — frozen, static, unable to access your world. A RAG system distributes intelligence across two places: the model’s reasoning capabilities, and your living, updateable, proprietary knowledge base.
That distribution is what makes AI products that work in the real world, not just in demos.
RAG has evolved from a simple research paper pattern to a production-critical architecture. The seven types — Naive, Advanced, Modular, Hybrid, Multimodal, Adaptive, and Agentic — give you a design vocabulary for matching architecture to problem complexity. The four levels of complexity give you a framework for scoping what kind of cognitive work your system needs to do.
The teams building reliable AI products in 2025 and 2026 have learned a consistent lesson: get the retrieval right before you optimize the generation. The quality of what you retrieve determines the ceiling of what you can generate. No LLM is good enough to fix bad retrieval.
Build your knowledge base like it’s a product. Evaluate your retrieval with the same rigor you’d apply to a feature. Test with real user queries, not curated demos.
That’s how RAG works at its best — not as a magic layer that makes LLMs smarter, but as a disciplined architecture that makes AI grounded in the truth of your domain.
FAQs
RAG stands for Retrieval-Augmented Generation. It's an architecture that lets an AI model look up relevant information from an external knowledge base before generating a response, rather than relying only on what it learned during training. The result is answers that are more accurate, more current, and grounded in documents that can be cited.
LLMs are trained on general public data up to a cutoff date. They don't know what happened after that date, they don't have access to your organization's private documents, and they can't cite specific sources. RAG solves all three of these limitations by adding a retrieval step that pulls relevant, specific, current information before the model responds.
RAG changes what the model can see at query time — it gives the model access to external documents. Fine-tuning changes how the model behaves — it updates the model's internal parameters to make it better at specific tasks, tones, or domains. Use RAG for knowledge that changes frequently or is proprietary. Use fine-tuning for stable behavioral adaptations. Many production systems use both together.
The seven types are: Naive RAG (basic retrieval without optimization), Advanced RAG (with pre- and post-retrieval optimization), Modular RAG (composable, flexible architecture), Hybrid RAG (combining vector and keyword search), Multimodal RAG (handling text, images, and other formats), Adaptive RAG (selective retrieval based on query type), and Agentic RAG (autonomous multi-step retrieval with planning).
The four levels describe the cognitive complexity of the queries your system handles. Level 1 is explicit fact retrieval (answer is directly stated in documents). Level 2 is implicit fact retrieval (answer must be synthesized from multiple sources). Level 3 is interpretable rationale (requires applying domain rules to retrieved facts). Level 4 is hidden rationale, also called multi-hop reasoning (requires iterative retrieval where each step informs the next).
RAG adds infrastructure complexity, latency, and maintenance overhead. If your knowledge base is small enough to fit in an LLM's context window (often under 200,000 tokens), full-context prompting with prompt caching may be simpler and cheaper. If your use case is pure content generation, code writing, or general reasoning with no proprietary knowledge requirements, a direct LLM call is sufficient.
Agentic RAG replaces the one-shot retrieval pipeline with an autonomous agent that plans, retrieves, evaluates whether the retrieved information is sufficient, and iterates — retrieving again from different sources or with different queries — until it has enough context to produce a complete answer. It's the right architecture for complex multi-hop queries, but requires trajectory-level evaluation because errors compound across each retrieval step.
The most common failure is poor retrieval, not poor generation. If the relevant documents aren't being retrieved — because of bad chunking, a poor embedding model, inappropriate chunk sizes, or a noisy knowledge base — no LLM is capable enough to compensate. Retrieval quality is the primary determinant of RAG system quality.
The four core metrics are: context recall (are the right documents being retrieved?), context precision (is what's being retrieved relevant?), faithfulness (is the answer grounded in the retrieved context?), and answer relevance (does the response address the question?). Evaluation should cover all three pipeline stages — retrieval, augmentation, and generation — independently, using a benchmark dataset that includes real user queries, edge cases, and adversarial examples. Tools like RAGAS provide frameworks for automated evaluation.
Semantic search retrieves the most relevant documents based on meaning rather than keywords, then stops — it surfaces documents. RAG takes the additional step of using those retrieved documents as context for an LLM to generate a synthesized, coherent response. RAG doesn't just find relevant content; it uses that content to answer a question.
Yes. RAG is model-agnostic by design. The retrieved context is passed to whatever LLM you're using as part of the prompt. You can use RAG with GPT-4o, Claude, Gemini, Llama 3, Mistral, or any other model that accepts text context. The best RAG systems are built to be LLM-agnostic specifically so they can switch between models without rebuilding the retrieval infrastructure.
Graph RAG uses a knowledge graph — a structured representation of entities and the relationships between them — as the retrieval source instead of or alongside a vector database. It's particularly effective for queries that require following relationship chains: "Who works for the company that acquired the company whose CEO gave the keynote?" These multi-hop relational queries are exactly what graph traversal handles well and what standard vector similarity search doesn't.

